
A 10-K filing is a comprehensive report filed annually by a publicly traded company about its financial performance in the US. The report contains much more detail than a company’s annual report. This report keeps investors aware of a company’s financial condition and to allow them to have enough information before investing in the firm’s corporate bonds. Company’s financial condition can be analyzed through various events like acquisition done, launch of a product, merger, beginning of stock trading, financial agreements, investment into some stock, lawsuit against company etc.
Problem Statement
The blog-post aims to demonstrate an event classification model which can extract all the major events occurred in the company’s 10-K filing document. This can help investors to know about health of any company from it’s 10-K filing document. The idea of the application was following.
- Download 10-K filings of 30 companies.
- Reads a filing as .htm format as input, parses .htm & converts into.txt format
- Splits all the text sentences contained in .txt file
- Extract list of all sentences where dates are mentioned (Use spacy entity recognition).
- Train text classification model: financial events vs non-events.
- Evaluation: classify test sentences into event vs non events class.
For the scope of this blog-post, I have shown building and training the text classification model with 2 classifiers namely Support Vector Machine(SVM) and Long Short Term Memory(LSTM) model.
Procedure
We downloaded 10-K filings of 30 companies, converted into text documents using Beautifulsoup and extracted all the dated sentences from the text documents using Spacy’s entity recognition. We did not considered text sentences which contained only year information i.e. dates detected by spacy had only 4 numbers. Mostly the financial events in 10-K filing were mentioned along with specific dates.
The processed data-set of 30 text documents can be found here. Further, all the text sentences with dates were manually labelled as events or non-events from domain expert. In total, there were approx. 2500 dated sentences from 10-filings of 30 companies that were labelled. The extracted sentences training data-set on which we worked can be downloaded from here.
Having said that, Let us walk through the following steps to build a text classification model for predicting financial event and non-event classes:
- Imports
- User-defined helper functions
- Reading Data
- Preparing Data for Model
- 4.1 Creating 2 class labels
- 4.2 Drop Duplicates
- 4.3 Extracting Features
- Building the Model
- 5.1 Support Vector Machine
- 5.2 LSTM Neural Network Model
- Evaluating the Model
- 6.1 Support Vector Machine
- 6.2 LSTM Neural Network Model
- Saving the Model
1. Imports
import pickle import numpy as np from sklearn.svm import SVC from sklearn import metrics from itertools import product import matplotlib.pyplot as plt from sklearn.model_selection import cross_val_score from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix from keras.preprocessing import sequence from keras.models import Sequential from keras.layers import Dense, LSTM from keras.layers.embeddings import Embedding from keras.preprocessing.text import Tokenizer import keras.preprocessing.text as kpt
2. Helper Functions
Below are the two helper functions used in this blog-post.
-
plot_confusion_matrixprints and plots the colored graphical confusion matrix. -
calculate_accuracy_metricscalculates and print accuracy metrics like precision, recall, f1_score and accuracy given actual and predicted labels as input.
def plot_confusion_matrix(cm, cmap=plt.cm.coolwarm):
"""
Description : This function prints and plots the confusion matrix.
Arguments : Confusion Matrix.
"""
classes = [0, 1]
title = 'Confusion matrix without normalization'
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
def calculate_accuracy_metrics(y_test,y_pred):
"""
Description: Calculates and print accuracy metrics like precision, recall, f1_score, accuracy
Arguments: True and Predicted labels
"""
precision = metrics.precision_score(y_test, y_pred)
recall = metrics.recall_score(y_test, y_pred)
fscore = metrics.f1_score(y_test, y_pred)
print("Precision = %.2f" % precision, "Recall = %.2f" % recall)
print("F1_score = %.2f" % fscore, "Accuracy = %.2f" % (np.sum(y_pred==y_test)/len(y_test)))
3. Reading Data
There are 5 columns as shown below in the data frame.
- cid – company id
- is_event – manually labelled flag whether it is financial event or not (for the company)
- context – context sentence in which the date occurred. (recognized by spacy)
- date – as detected by spacy entity recognition
- line_id – unique id for each sentence
labelled_df = pd.read_excel("30_companies_filings_event_nonevent_final_data.xlsx", index_col=False)
labelled_df.head()

4. Preparing Data for Model
labelled_df['is_event'].value_counts()

labelled_df.columns
Index(['cid', 'is_event', 'context', 'Date', 'line_id'], dtype='object')
There were few sentences where multiple financial dated events occurred in one context sentence. Such text sentences were initially labelled “2” or “3” by domain expert in is_event flag column. For classification model, we considered only 2 classes irrespective of number of events occurring in one context sentence.
4.1 Creating 2 class labels
labelled_df['is_event'] = np.where(labelled_df['is_event']>=1.0, 1, 0) labelled_df['is_event'].value_counts()

4.2 Drop Duplicates
labelled_df = labelled_df.drop_duplicates(subset='context', keep="first") labelled_df['is_event'].value_counts()

4.3 Extracting Features
It is obvious that “context” text column is the input to our machine learning models and “is_event” column is the target label.
text_lines = labelled_df['context'] Y = labelled_df['is_event'] text_lines[0]

Now, we will be extracting a most popular and widely adopted word weighing scheme in text mining problems, known as term frequency and inverse document frequency (tf-idf). Further in next section, we will be training a SVM classifier after splitting the data-set into train and test sets (80:20).
X_train, X_test, y_train, y_test = train_test_split(text_lines, Y,
test_size=0.2,
stratify=Y, random_state=42)
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(X_train)
print("Shape of X = ", X.shape)
print("Size of labels = ",len(y_train))

5 Building the Model
5.1 Support Vector Machine
# Initializing the model clf = SVC(kernel='linear',class_weight='balanced', probability=True) # Training the model clf.fit(X,y_train)

Finally, we analyse the performance of the trained SVM model using tf-idf scheme in next section.
5.2 LSTM Neural Network Model
For LSTM based model, words are features, hence the bag-of-words model can be used to create a feature vector. It can be done in following steps:
- Make a dictionary : We create a dictionary containing word-index tuples of all the distinct words in training text sentences. We assume that the ordering of words is not important.
- Convert words of each text sentences into word index array and store the index array of each sentence in global list.
- Convert the global list of index into a feature matrix. Each text sentence is represented by a sparse vector of the size of maximum sentence length size (i.e 100 here), with 0 padded in the entries where sentence length is less than 100. Thus the final training feature matrix will be of shape (1768, 100).
The python code snippet for demonstrating feature extraction is shown below.
def convert_text_to_index_array(text):
return [dictionary[word] for word in kpt.text_to_word_sequence(text)]
# Create Dictionary of words and their indices
max_words = 4000
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(text_lines)
dictionary = tokenizer.word_index
# Replace words of each text review to indices
allWordIndices = []
for num,text in enumerate(X_train):
wordIndices = convert_text_to_index_array(text)
if num==0:
print(text)
allWordIndices.append(wordIndices)
# truncate and pad input sequences
max_sent_length = 100
train_X = sequence.pad_sequences(allWordIndices, maxlen=max_sent_length)
print("\n Word Index array \n")
print(allWordIndices[0])
print("\n Feature Matrix \n")
print(train_X[0,:])
print("\n Shape of feature matrix = ", train_X.shape)

Further, we will train a LSTM classifier on train set. Finally, we analyze the performance of the trained LSTM based classification model on test set in next section.
embedding_length = 32 model = Sequential() model.add(Embedding(max_words, embedding_length, input_length=max_sent_length)) model.add(LSTM(50)) model.add(Dense(1,activation="sigmoid")) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) print(model.summary()) model.fit(train_X, y_train, epochs=10, batch_size=32)
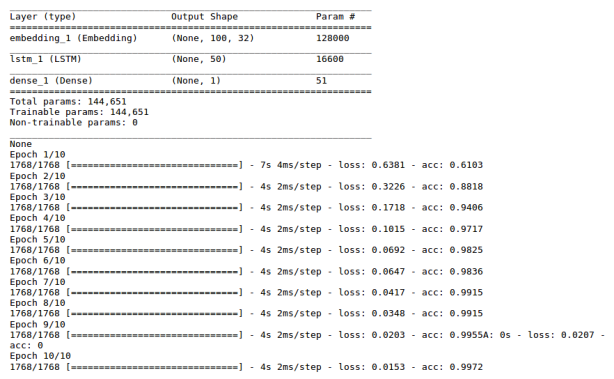
6 Evaluating the Model
In this section, we evaluate the trained models on test set(20%) to check the performance.
6.1 Support Vector Machine
x_test = vectorizer.transform(X_test) y_pred = clf.predict(x_test) cm = confusion_matrix(y_test, y_pred) calculate_accuracy_metrics(y_test, y_pred) plot_confusion_matrix(cm)

6.2 LSTM Neural Network Model
# Replace words of each text review to indices
testWordIndices = []
for num,text in enumerate(X_test):
wordIndices = convert_text_to_index_array(text)
testWordIndices.append(wordIndices)
test_X = sequence.pad_sequences(testWordIndices, maxlen=max_sent_length)
y_pred = model.predict(test_X)
y_pred = np.where(y_pred > 0.5,1,0).ravel()
cm = confusion_matrix(y_test, y_pred)
calculate_accuracy_metrics(y_test, y_pred)
plot_confusion_matrix(cm)

7 Saving the Model
One can save the trained tf-idf vectorizer and trained machine learning model (SVM) for prediction purpose like shown below.
Modelfilename = 'event_classification_model.pkl' pickle.dump(clf, open(Modelfilename, 'wb')) Vectorizerfilename = 'event_vectorizer_model.pkl' pickle.dump(vectorizer, open(Vectorizerfilename, 'wb'))
At the End
Hope it was easy to follow the tutorial. Beginners interested in text analytics/NLP can start with this application. Readers are strongly encouraged to download the data-set and check if they can reproduce the results. Readers can discuss in comments if there is a need of an explicit explanation.
Few points worth noting are:
- LSTM model under performed because the data was not sufficient enough. The dates text sentences were hardly 2K which is very less volume if deep learning models are to be considered.
- We can also categorize dated text sentences into high, medium and low chances of being a financial event using confidence in prediction (probability score of trained ML model).
- Majorly, analyzing the data-set, most of the financial dated events are company’s incorporation, acquisition of subsidiary company, launch of a product, merger, beginning of stock trading, financial agreements, investment into some stock, company name change, lawsuit against company, joining of a key person, being awarded etc. These events can narrate a story of a company in a historical timeline.
- A whole end to end application can be developed by building the pipeline from parsing a 10-K html filing to highlighting (in colors) the financial events in 10-K filing report.
If you liked the post, follow this blog to get updates about upcoming articles. Also, share it so that it can reach out to the readers who can actually gain from this. Please feel free to discuss anything regarding the post. I would love to hear feedback from you.
Happy machine learning 🙂
I want you to thank for your time of this wonderful read!!! I definately enjoy every little bit of it and I have you bookmarked to check out new stuff of your blog a must read blog!
best training institutions
Like
The content is well acknowledged, so no one could allege that it is just one person’s opinion yet it covers and justifies all the applicable points. I have read such a startling work after a long timeThe content is well acknowledged, so no one could allege that it is just one person’s opinion yet it covers and justifies all the applicable points. I have read such a startling work after a long time
Like