
Logistic Regression and Naive Bayes are two most commonly used statistical classification models in the analytics industry. Logistic Regression, a discriminative model, assumes a parametric form of class distribution Y given data X, P(Y|X), then directly estimates its parameters from the training data. On the other hand, Naive Bayes classifier, a generative model uses Bayes rule for learning P(Y|X) where X=〈X1…, Xn〉, and does this by making a conditional independence assumption that dramatically reduces the number of parameters to be estimated when modeling likelihood P(X|Y).
One of the inquisitive fact is the equivalence between Logistic Regression (LR) and Gaussian Naive Bayes (GNB) model. Gaussian Naive Bayes is simple naive bayes with a typical assumption that the continuous features associated with each class are distributed according to a normal (or Gaussian) distribution. This post is a theoretical explanation to show that Gaussian Naive Bayes and Logistic Regression are precisely learning the same boundary under certain assumptions. Before that let us quickly look at LR and GNB separately.
1. Logistic Regression (LR)
Logistic Regression assumes a parametric form for the distribution P(Y|X), then directly estimates its parameters from the training data. It is an approach to learning functions of the form f:X→Y, or P(Y|X) in the case where Y is discrete-valued (for eg. 0 and 1), and X= 〈X1… Xn〉 is any vector containing discrete or continuous variables/features. For example, Y can be classes to be predicted as cat and dog. X could be a vector form of pixel values of an image having either of the classes (cat or dog). LR algorithms learns the parameters w as coefficients for each of the variables/features.
The parametric model assumed by Logistic Regression in the case where Y is boolean is:

We have a linear classification rule that assigns label Y=0 if X satisfies,
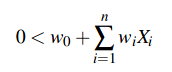
and assigns Y=1 otherwise. The below image can be seen as form of the logistic function.

2. Gaussian Naive Bayes (GNB)
Let us now derive the Naive Bayes algorithm, assuming in general that Y is any discrete-valued variable, and the attributes X1…Xn are any discrete or real-valued attributes. Our goal is to train a classifier that will output the probability distribution over possible values of Y, for each new instance X that we ask it to classify. The expression for the probability that Y will take on its kth possible value, assuming that Xi are conditionally independent given Y, according to Bayes rule, is

where the sum is taken over all possible values yj of Y. If we are interested only in the most probable value of Y, then we have the Naive Bayes classification rule:

which simplifies to the following (because the denominator does not depend on yk).

One way to create a simple model is assume that the data is described by a Gaussian distribution with no co-variance (independent dimensions) between dimensions. This model can be fit by simply finding the mean and standard deviation of the points within each label, which is all you need to define such a distribution. The result of this naive Gaussian assumption is shown in the following figure:

The ellipses here represent the Gaussian generative model for each label, with larger probability toward the center of the ellipses. With this generative model in place for each class, we have a simple recipe to compute the likelihood P(features|L1) for any data point, and thus we can quickly compute the posterior ratio and determine which label is the most probable for a given point.
3. LR-GNB Equivalence
Here we derive the form of P(Y|X) entailed by the assumptions of a Gaussian Naive Bayes (GNB) classifier, showing that it is precisely the form used by Logistic Regression and summarized in equations given in Section 1. In particular, consider a GNB based on the following modeling assumptions:
- Y is boolean, governed by a Bernoulli distribution, with parameter π=P(Y=1)
- X=〈X1…Xn〉, where each Xi is a continuous random variable
- For each Xi, P(Xi|Y=yk) is a Gaussian distribution of the form N(μik,σi)
- For all i and j not eq i, Xi and Xj are conditionally independent given Y
Note here we are assuming the standard deviations σi vary from attribute to attribute, but do not depend on Y. We now derive the parametric form of P(Y|X) that follows from this set of GNB assumptions. In general, Bayes rule allows us to write
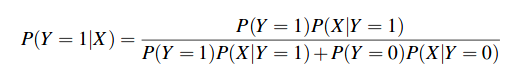
Dividing both the numerator and denominator by the numerator yields:
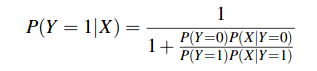 or equivalently
or equivalently

Because of our conditional independence assumption we can write this

Note the final step expresses P(Y=0) and P(Y=1) in terms of the binomial parameter π. Now consider just the summation in the denominator of equation above. Given our assumption that P(Xi|Y=yk) is Gaussian, we can expand this term as follows:

Note this expression is a linear weighted sum of the Xi’s. Substituting above expression back into previous equation , we have

Or equivalently,

where the weights w1…wn are given by

and where

Also we have

The above subsection proves that P(Y|X) can be expressed in the parametric form given by Logistic Regression, under the Gaussian Naive Bayes assumptions detailed there. It also provides the value of the weights wi in terms of the parameters estimated by the GNB classifier.
Conclusion
This blog was an effort to give a comprehensive idea behind the two statistical models namely Logistic Regression and Naive Bayes and deriving the equivalence between them under certain assumptions, albeit with much of the details regarding individual models intentionally skipped. Readers are encouraged to delve more into the mathematical formulation and to discuss it with us, and to also let us know about any more concepts they would like to be elaborated upon in the comments. It will motivate to cover those concepts in future posts.
If you liked the post, follow this blog to get updates about the upcoming articles. Also, share this article so that it can reach out to the readers who can actually gain from this. All comments and suggestions from all the readers are welcome.
Happy machine learning 🙂
thanks for sharing wonderful article. keep posting!
Like
Thanks.
Like
Nice Post. Thanks for sharing.
I am looking for details in the mathematical part (manual calculation), any suggestion? Thanks.
Like
For calculation w, What is u0 and u1?
Like
It’s a boolean example here. So, u0 and u1 would be mean of respective distributions (classes)
Like