Much recently in October, 2018, Google released new language representation model called BERT, which stands for “Bidirectional Encoder Representations from Transformers”. According to their paper, It obtains new state-of-the-art results on wide range of natural language processing tasks like text classification, entity recognition, question and answering system etc.
In December, 2017, I had participated in one HackerEarth Challenge, “Predict the Happiness” where I build a multi-layered fully connected Neural Network for this text classification problem (Predict the Happiness). I could get 87.8% accuracy from the submitted solution on the test data. My rank was 66 on the leader board of the challenge. I had penned down the solution that time in my blog-post here.
Having so much of discussion around BERT over internet, I chose to apply BERT in the same competition in order to prove if tuning BERT model can take me to the top of leader board of the challenge. I would recommend reading my previous blog-post to know about data-set, problem statement and solution. So, let’s start.
1. Installation
As far as tensorflow based installation are concerned, It is easy to set up the experiment. In your python tensorflow environment, just follow these two steps.
- Clone the BERT Github repository onto your own machine. On your terminal, type
git clone https://github.com/google-research/bert.git - Download the pre-trained model from official BERT Github page here. There are 4 types of per-trained models.
BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parameters
BERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parameters
BERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parameters
BERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parameters
I downloaded the BERT-Base, Cased one for the experiment as the text data-set used had cased words. Also, base models are only 12 layers deep neural network (as opposed to BERT-Large which is 24 layers deep) which can run on GTX 1080Ti (11 GB VRAM). BERT-Large models can not run on 11 GB GPU memory and it would require more space to run (64GB would suffice).
2. Preparing Data for Model
We need to prepare the text data in a format that it complies with BERT model. Basically codes written by Google to apply BERT accepts the “Tab separated” file in following format.
train.tsv or dev.tsv
- an ID for the row
- the label for the row as an int (class labels: 0,1,2,3 etc)
- A column of all the same letter (weird throw away column expected by BERT)
- the text examples you want to classify
test.tsv
- an ID for the row
- the text sentences/paragraph you want to test
The below python code snippet would read the HackerEarth training data (train.csv) and prepares it according to BERT model compliance.
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from pandas import DataFrame
le = LabelEncoder()
df = pd.read_csv("data/train.csv")
# Creating train and dev dataframes according to BERT
df_bert = pd.DataFrame({'user_id':df['User_ID'],
'label':le.fit_transform(df['Is_Response']),
'alpha':['a']*df.shape[0],
'text':df['Description'].replace(r'\n',' ',regex=True)})
df_bert_train, df_bert_dev = train_test_split(df_bert, test_size=0.01)
# Creating test dataframe according to BERT
df_test = pd.read_csv("data/test.csv")
df_bert_test = pd.DataFrame({'User_ID':df_test['User_ID'],
'text':df_test['Description'].replace(r'\n',' ',regex=True)})
# Saving dataframes to .tsv format as required by BERT
df_bert_train.to_csv('data/train.tsv', sep='\t', index=False, header=False)
df_bert_dev.to_csv('data/dev.tsv', sep='\t', index=False, header=False)
df_bert_test.to_csv('data/test.tsv', sep='\t', index=False, header=True)
The below image shows the head() of pandas dataframe “df” which actual training data from the challenge (train.csv).

With the above python codes, we have changed the above train.csv format into BERT complied format as shown in below image.

Similarly, test.csv is also read in the data frame and converted as described earlier. Finally, all the data frames are converted into tab separated file “.tsv”.
3. Training Model using Pre-trained BERT model
Following the blog-post till here finishes half of the job. Just recheck the following things.
- All the .tsv files are in a folder having name “data”
- Make sure you have created a folder “bert_output” where the fine tuned model will be saved and test results are generated under the name “
test_results.tsv“ - Check that you downloaded the pre-trained BERT model in current directory “cased_L-12_H-768_A-12”
- Also, ensure that the paths in the command are relative path (starts with “./”)
One can now fine tune the downloaded pre-trained model for our problem data-set by running the below command on terminal:
python run_classifier.py --task_name=cola --do_train=true --do_eval=true --do_predict=true --data_dir=./data/ --vocab_file=./cased_L-12_H-768_A-12/vocab.txt --bert_config_file=./cased_L-12_H-768_A-12/bert_config.json --init_checkpoint=./cased_L-12_H-768_A-12/bert_model.ckpt --max_seq_length=400 --train_batch_size=8 --learning_rate=2e-5 --num_train_epochs=3.0 --output_dir=./bert_output/ --do_lower_case=False
It generates “test_results.tsv” in output directory as a result of predictions on test data-set. It contains predicted probability value of all the classes in column wise.
4. Preparing Results for Submission
The below python code converts the results from BERT model to .csv format in order to submit to HackerEarth Challenge.
df_results = pd.read_csv("bert_output/test_results.tsv",sep="\t",header=None)
df_results_csv = pd.DataFrame({'User_ID':df_test['User_ID'],
'Is_Response':df_results.idxmax(axis=1)})
# Replacing index with string as required for submission
df_results_csv['Is_Response'].replace(0, 'happy',inplace=True)
df_results_csv['Is_Response'].replace(1, 'not_happy',inplace=True)
# writing into .csv
df_results_csv.to_csv('data/result.csv',sep=",",index=None)



The above figure shows the conversion of probability values into submission results.
Power of BERT
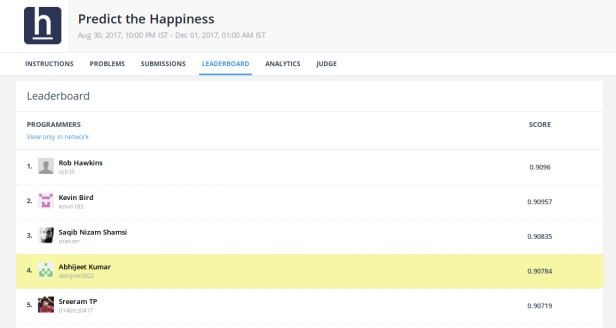
I submitted the file result.csv to HackerEarth “Predict the Happiness challenge” and became Leaderboard Rank 4. Imagine the accuracy and rank if I could use the larger model instead of Base model.
Finally about BERT
It is a new method of pre-training language representations which obtains state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks. The research paper from Google that proposes BERT is found here. It is a must read.
Training ?
The model is pre-trained using two novel unsupervised prediction tasks:
BERT uses a simple approach for this: Mask out 15% of the words in the input, run the entire sequence through a deep Bidirectional Transformer encoder, and then predict only the masked words. For example:
Input: the man went to the [MASK1] . he bought a [MASK2] of milk.
Labels: [MASK1] = store; [MASK2] = gallon
In order to learn relationships between sentences, we also train on a simple task which can be generated from any monolingual corpus: Given two sentences A and B, is B the actual next sentence that comes after A, or just a random sentence from the corpus ?
Sentence A: the man went to the store.
Sentence B: he bought a gallon of milk.
Label: IsNextSentence
Sentence A: the man went to the store.
Sentence B: penguins are flightless.
Label: NotNextSentence
Architecture ?
There are two models pre-trained depending on the scale of the model architecture namely BASE and LARGE.
BERT BASE:
Number of Layers =12
No. of hidden nodes = 768
No. of Attention heads =12
Total Parameters = 110M
BERT LARGE:
Number of Layers =24,
No. of hidden nodes = 1024
No. of Attention heads =16
Total Parameters = 340M
The TensorFlow code and pre-trained models for BERT are present in GitHub link here.
Fine Tuning ?
For sequence-level classification tasks, BERT fine-tuning is straight forward. The only new added parameters during fine-tuning are for a classification layer W ∈ (K×H), where ‘K’ is the number of classifier labels and ‘H’ is the number of final hidden states. The label probabilities for K classes are computed with a standard soft-max. All of the parameters of BERT and ‘W’ are fine-tuned jointly to maximize the log-probability of the correct label.
Use of Transformers ?
I found the explanation provided in this and this link useful and explanatory in terms of BERT and how BERT is based on the idea of using transformers with attentions. Transformers have changed the usual encoder decoder (RNNs/LSTMs) implementations. A must read paper on Transformers “Attention is all you need” which has fundamentally replaced the encoder-decoder architecture as transformers are superior in quality (removes the shortcoming of training long sequences in RNNs/LSTMs) while being more parallelizable and requiring significantly less time to train.
If you liked the post, follow this blog to get updates about upcoming articles. Also, share it so that it can reach out to the readers who can actually gain from this. Please feel free to discuss anything regarding the post. I would love to hear feedback from you.
Happy Deep Learning 🙂
what about all other coloumns in dataset? have u dropped them?what is difference between UserID and ID coloumn? what is this throw coloumn for? are we suppose to keep it incase we are using foreign language dataset?
Liked by 1 person
Hi Sam,
I think I explicitly forgot to mention as I had written another blog-post on the same challenge an year back. https://appliedmachinelearning.blog/2017/12/21/predict-the-happiness-on-tripadvisor-reviews-using-dense-neural-network-with-keras-hackerearth-challenge/
So answer your queries,
– Yes I dropped them.
– UserID was given in dataset, ID is generated automatically by pandas.
– Yes throw away column is necessary as BERT model accepts input in that format only.
– Yes I suppose you will have to use the same input format.
Like
Hi abhi,
Thanks for reply, and by the way excellent post.
There is another query am doing multi class classfication and m labels are strings, when i am trying to tranform it the way you did inn your blog , its generates an errror , or I can keep the label type intact
Like
Hey,
You can not keep the labels as strings.
The labels has to be an int (class labels: 0,1,2,3 etc).
Just debug the error. Use LabelEncoder to do so.
Thanks.
Like
How do I generate user id and isResponse for dataframe object.
df_bert = pd.DataFrame({‘user_id’:df[‘User_ID’],
‘label’:le.fit_transform(df[‘Is_Response’]),
‘alpha’:[‘a’]*df.shape[0],
‘text’:df[‘Description’].replace(r’\n’,’ ‘,regex=True)
This line gives me key error:user id
Best,
Cartik
Like
I have tried it with labelencoder as wel but dont u think it creates problem as wel , as i have 13 classes ,which will be categorical data but as said in one of blog
“The problem here is, since there are different numbers in the same column, the model will misunderstand the data to be in some kind of order, 0 < 1 < 2. But this isn’t the case at all. To overcome this problem, we use One Hot Encoder."
So what is way out of it? Or BERT cant understand this string at all
Liked by 1 person
Let me clarify on this.
If you have 13 classes then simply replace the categorical labels in 0-12 integer.
It is true that
Any categorical feature should never be changed in integer because it can misunderstand it as some order as you said 0<1<2. So one hot encoding is done to avoid that.
But here the categorical column is the classes you want to predict (labels or Y). The above fact is true for the features which is fetched in the model not for the label you want to predict. Any models learns from features not from class labels.
Again, I will re-iterate my point. Simply convert categories in class label as integer.
It is obvious that no deep learning model will accept string as output layer as output layer in neural network has to be a sigmoid or softmax which will have 13 nodes (0-12 as number of classes). BERT implementation requires classes to be integers.
Hope I am clear now. It is very easy to convert categorical strings to integer numbers. Please debug your error. If LabelEncoder is not working then simply make a dictionary mapping and replace the strings in integer numbers.
Thanks
Like
Hello
I am using multilanguage model recommended at bert repository for hindi text classification on 5 classes , after following all the steps i am getting error regarding tokenization.py that do_lower _case = false , where as mode checkpoint expect TRUE or comment it
I did all variations but still not succeded
Liked by 1 person
Hey Saira,
I have not tried multilanguage models.
I will suggest you to report it as an issue at their github repository.
Like
it throws this error, can you help me fix it.
Traceback (most recent call last):
File “run_classifier.py”, line 981, in
tf.app.run()
File “/usr/local/lib/python3.6/dist-packages/tensorflow/python/platform/app.py”, line 125, in run
_sys.exit(main(argv))
File “run_classifier.py”, line 820, in main
vocab_file=FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)
File “/content/gdrive/My Drive/jigsaw_tox/bert/tokenization.py”, line 165, in __init__
self.vocab = load_vocab(vocab_file)
File “/content/gdrive/My Drive/jigsaw_tox/bert/tokenization.py”, line 127, in load_vocab
token = convert_to_unicode(reader.readline())
File “/usr/local/lib/python3.6/dist-packages/tensorflow/python/lib/io/file_io.py”, line 183, in readline
self._preread_check()
File “/usr/local/lib/python3.6/dist-packages/tensorflow/python/lib/io/file_io.py”, line 85, in _preread_check
compat.as_bytes(self.__name), 1024 * 512, status)
File “/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/errors_impl.py”, line 528, in __exit__
c_api.TF_GetCode(self.status.status))
tensorflow.python.framework.errors_impl.NotFoundError: ; No such file or directory
Liked by 1 person
I would suggest you to look this error and try to debug.
Seems like you are using windows and may be giving some wrong path.
Kindly set the paths properly (specially vocab.txt path) and run the command.
Like
this same procedure is not working for multiclass problem, i am running it for 5 classes, changed colaprocessor() in run_classifier.py as
def get_labels(self):
“””See base class.”””
return [“0”, “1”,”2″,”3″,”4″,”5″]
but its giving me following error
C:\Users\lenovo\AppData\Roaming\Python\Python36\site-packages\absl\flags\_validators.py:358: UserWarning: Flag –task_name has a non-None default value; therefore, mark_flag_as_required will pass even if flag is not specified in the command line!
‘command line!’ % flag_name)
Traceback (most recent call last):
File “run_classifier.py”, line 928, in
tf.app.run()
File “C:\Users\lenovo\AppData\Roaming\Python\Python36\site-packages\tensorflow\python\platform\app.py”, line 125, in run
_sys.exit(main(argv))
File “run_classifier.py”, line 798, in main
train_examples, train_labels, temp = processor.get_train_examples(FLAGS.data_dir)
File “run_classifier.py”, line 302, in get_train_examples
self._read_tsv(os.path.join(data_dir, “train.tsv”)), “train”)
File “run_classifier.py”, line 330, in _create_examples
text_a = tokenization.convert_to_unicode(line[3])
IndexError: list index out of range
Like
is not //return [“0”, “1”,”2″,”3″,”4″,”5″]// 6 classes ?
Like
Thank you. Excellent post!
Does the fine-tuning section in your post updates the weights of the pre-trained BERT over the new text?
Liked by 1 person
Yes. It updates the weights of pre-trained BERT model over new text. Going by the command, it would iterate 3 epochs on new text.
Like
Seems this approach wouldnt work with multiclass problem of bert , though i have changed get_label as well from return [0,1] to number of classes in my corpus , but its still throwing following error, any leads will be appreciated
lenovo-FT6BC8M MINGW64 /d/research/Classification_bert (master)
Traceback (most recent call last):
File “run_classifier.py”, line 982, in
tf.app.run()
File “C:\Users\lenovo\AppData\Roaming\Python\Python36\site-packages\tensorflow\python\platform\app.py”, line 125, in run
_sys.exit(main(argv))
File “run_classifier.py”, line 843, in main
train_examples = processor.get_train_examples(FLAGS.data_dir)
File “run_classifier.py”, line 342, in get_train_examples
self._read_tsv(os.path.join(data_dir, “train.tsv”)), “train”)
File “run_classifier.py”, line 371, in _create_examples
text_a = tokenization.convert_to_unicode(line[3])
IndexError: list index out of range
Like
I was running into the same error. Even after reducing my number of classes to `[0,1]`, making sure that I had both classes in the test and dev sets, and removing all rows with any `na` values. However, I continued getting this error. I then cleaned my text so that it only contained [a-z0-9], i.e. removed all other characters other than letters and numbers. Bert then ran successfully.
Like
hey i get key error 43….Can anyone assist me in overcomming this
>python run_classifier.py –task_name=cola –do_train=true –do_eval=true –do_predict=true –data_dir=./data/ –vocab_file=./cased_L-12_H-768_A-12/vocab.txt –bert_config_file=./cased_L-12_H-768_A-12/bert_config.json –init_checkpoint=./cased_L-12_H-768_A-12/bert_model.ckpt –max_seq_length=400 –train_batch_size=8 –learning_rate=2e-5 –num_train_epochs=3.0 –output_dir=./bert_output/ –do_lower_case=False
WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
If you depend on functionality not listed there, please file an issue.
WARNING:tensorflow:Estimator’s model_fn () includes params argument, but params are not passed to Estimator.
INFO:tensorflow:Using config: {‘_model_dir’: ‘./bert_output/’, ‘_tf_random_seed’: None, ‘_save_summary_steps’: 100, ‘_save_checkpoints_steps’: 1000, ‘_save_checkpoints_secs’: None, ‘_session_config’: allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: ONE
}
}
, ‘_keep_checkpoint_max’: 5, ‘_keep_checkpoint_every_n_hours’: 10000, ‘_log_step_count_steps’: None, ‘_train_distribute’: None, ‘_device_fn’: None, ‘_protocol’: None, ‘_eval_distribute’: None, ‘_experimental_distribute’: None, ‘_service’: None, ‘_cluster_spec’: , ‘_task_type’: ‘worker’, ‘_task_id’: 0, ‘_global_id_in_cluster’: 0, ‘_master’: ”, ‘_evaluation_master’: ”, ‘_is_chief’: True, ‘_num_ps_replicas’: 0, ‘_num_worker_replicas’: 1, ‘_tpu_config’: TPUConfig(iterations_per_loop=1000, num_shards=8, num_cores_per_replica=None, per_host_input_for_training=3, tpu_job_name=None, initial_infeed_sleep_secs=None, input_partition_dims=None), ‘_cluster’: None}
INFO:tensorflow:_TPUContext: eval_on_tpu True
WARNING:tensorflow:eval_on_tpu ignored because use_tpu is False.
INFO:tensorflow:Writing example 0 of 156251
Traceback (most recent call last):
File “run_classifier.py”, line 981, in
tf.app.run()
File “C:\Users\kuruparans\AppData\Local\Programs\Python\Python37\lib\site-packages\tensorflow\python\platform\app.py”, line 125, in run
_sys.exit(main(argv))
File “run_classifier.py”, line 870, in main
train_examples, label_list, FLAGS.max_seq_length, tokenizer, train_file)
File “run_classifier.py”, line 490, in file_based_convert_examples_to_features
max_seq_length, tokenizer)
File “run_classifier.py”, line 459, in convert_single_example
label_id = label_map[example.label]
KeyError: ’43’
>python run_classifier.py –task_name=cola –do_train=true –do_eval=true –do_predict=true –data_dir=./data/ –vocab_file=./cased_L-12_H-768_A-12/vocab.txt –bert_config_file=./cased_L-12_H-768_A-12/bert_config.json –init_checkpoint=./cased_L-12_H-768_A-12/bert_model.ckpt –max_seq_length=400 –train_batch_size=8 –learning_rate=2e-5 –num_train_epochs=3.0 –output_dir=./bert_output/ –do_lower_case=False
WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
If you depend on functionality not listed there, please file an issue.
WARNING:tensorflow:Estimator’s model_fn () includes params argument, but params are not passed to Estimator.
INFO:tensorflow:Using config: {‘_model_dir’: ‘./bert_output/’, ‘_tf_random_seed’: None, ‘_save_summary_steps’: 100, ‘_save_checkpoints_steps’: 1000, ‘_save_checkpoints_secs’: None, ‘_session_config’: allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: ONE
}
}
, ‘_keep_checkpoint_max’: 5, ‘_keep_checkpoint_every_n_hours’: 10000, ‘_log_step_count_steps’: None, ‘_train_distribute’: None, ‘_device_fn’: None, ‘_protocol’: None, ‘_eval_distribute’: None, ‘_experimental_distribute’: None, ‘_service’: None, ‘_cluster_spec’: , ‘_task_type’: ‘worker’, ‘_task_id’: 0, ‘_global_id_in_cluster’: 0, ‘_master’: ”, ‘_evaluation_master’: ”, ‘_is_chief’: True, ‘_num_ps_replicas’: 0, ‘_num_worker_replicas’: 1, ‘_tpu_config’: TPUConfig(iterations_per_loop=1000, num_shards=8, num_cores_per_replica=None, per_host_input_for_training=3, tpu_job_name=None, initial_infeed_sleep_secs=None, input_partition_dims=None), ‘_cluster’: None}
INFO:tensorflow:_TPUContext: eval_on_tpu True
WARNING:tensorflow:eval_on_tpu ignored because use_tpu is False.
INFO:tensorflow:Writing example 0 of 156251
Traceback (most recent call last):
File “run_classifier.py”, line 981, in
tf.app.run()
File “C:\Users\kuruparans\AppData\Local\Programs\Python\Python37\lib\site-packages\tensorflow\python\platform\app.py”, line 125, in run
_sys.exit(main(argv))
File “run_classifier.py”, line 870, in main
train_examples, label_list, FLAGS.max_seq_length, tokenizer, train_file)
File “run_classifier.py”, line 490, in file_based_convert_examples_to_features
max_seq_length, tokenizer)
File “run_classifier.py”, line 459, in convert_single_example
label_id = label_map[example.label]
KeyError: ’43’
C:\Users\kuruparans\bert>
Like
got it solved
by correcting cola processor class
Like
I made all the three files in the required format. I am getting an error on executing run_classifier.py.
Traceback (most recent call last):
File “C:\Users\45063192\bert\run_classifier.py”, line 981, in
tf.app.run()
File “C:\Users\45063192\AppData\Local\Continuum\anaconda3\lib\site-packages\tensorflow\python\platform\app.py”, line 125, in run
_sys.exit(main(argv))
File “C:\Users\45063192\bert\run_classifier.py”, line 870, in main
train_examples, label_list, FLAGS.max_seq_length, tokenizer, train_file)
File “C:\Users\45063192\bert\run_classifier.py”, line 490, in file_based_convert_examples_to_features
max_seq_length, tokenizer)
File “C:\Users\45063192\bert\run_classifier.py”, line 459, in convert_single_example
label_id = label_map[example.label]
KeyError: ‘2’
I’m getting the error after it processes a few lines from my files
Like
how much time it usually takes to run?
Like
depends on data and GPU usage. For me. 1080TI GPU and this data-set, It only took few minutes.
Like
Hi,
I can’t see when you specify the use of your GPU. If I run this code just like you, it only uses my CPU.
Can I have some help on that?
Thanks!
Like
Hi,
If you have installed “tensorflow-gpu” package, it automatically uses GPU.
If you installed “tensorflow” package, it uses CPUs.
Thanks.
Like
Hello, where is the run_classifier.py file?
Thank you
Like
Hi, run_classifier.py is in BERT directory. Check its Github link.
Like
error in import modeling
No matching distribution found for modeling
please help
i am running code of run_classifier in jupyter kaggle notebook
Like
Hi Abhijeet,
Thanks for your post. I’m trying to create train/dev/test tsv files based on your code. After reading csv file into a DataFrame I get an error called keyerror:user id.
File “pandas\_libs\index_class_helper.pxi”, line 91, in pandas._libs.index.Int64Engine._check_type
KeyError: ‘User_ID’
df_bert = pd.DataFrame({‘user_id’:df[‘User_ID’],
‘label’:le.fit_transform(df[‘Is_Response’]),
‘alpha’:[‘a’]*df.shape[0],
‘text’:df[‘Description’].replace(r’\n’,’ ‘,regex=True)})
Can you help me resolve this, what would be a possible solution?
Like