
Why should we bother ??
Distributions plays a very crucial role in data science and analytics. Statistical distributions shows us the underlying relationship between the data points. The main purpose of checking distributions is to get an idea on how the data points of the target are spread across, so that appropriate model could be used to fit. For non data-science folks, by target we are referring the variable upon which we are interested to do some prediction or estimation.
The examples below will justify the need for distribution:
The majority of popular statistical models including the most common kinds, say linear regression make an assumption of normally distributed error terms. In another example of insurance industry, if we want to see the distribution of number of claims that come for each policy then ideally it will look like Poisson distribution, as we are concerned about the count of claim, which is discrete in nature.
Blog-post Content
Although, the list of distributions are huge, but that scope of this blog-post is to cover the ones which we use more commonly in the industry. The list shortens to 5 major distributions and one bonus distribution which is very common to insurance industry. They are:
- Normal Distribution
- Binomial Distribution
- Uniform Continuous Distribution (Rectangular Distribution)
- Poisson Distribution
- Gamma Distribution
- Tweedie Distribution
Normal, rectangular and gamma are used for continuous variables, poisson and binomial are for discrete variables and tweedie distribution is one such distribution which models both poisson and gamma together.
For each of the distribution, we will be looking at:
- Brief explanation with mathematical description
- Generating each distribution in Python.
- Plotting with Seaborn library
1. Normal Distribution
Normal distribution is one of the most common distribution and is used for continuous variables. It is bell shaped curve which is neither too skewed not too flat and has parameters: 
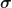
The probability density function for normal distribution is :

Properties of Normal Distrbution
- Symmetric around the mean i.e. all the basic summary stats: mean, median and mode lies at the center and are equal to each other
- Standard deviation represents how closely packed or loosely floating are the data points to or away from the mean
- Since the distribution is symmetric, so area under the curve is equal to 1
- When
and
then the distribution is called standard normal distrbution
We will be using np.random.normal() from numpy package to generate random sample of normally distributed variates. The np.random.normal() has three parameters : loc (mean), scale (SD) and size (no.of obs to be generated).
The below code will show how to generate random sample for normal distribution and the shape of the distribution.
#Import Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
# Normal Distribution
#Intializing the parameters: mean and SD
mu1,sigma1 = 2,2
np.random.seed(seed=32)
s_normal= np.random.normal(mu1, sigma1, 200000)
plt.subplots(figsize=(10,5))
plot=sns.distplot(pd.DataFrame(s_normal)).set_title('Normal Distribution with $\mu$=%.1f,$\sigma$=%.1f'%(mu1,sigma1))
fig=plot.get_figure()

We know that 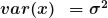
print(np.mean(s_normal), np.var(s_normal))
we are getting mean as 2.007 and variance as 4.005. The values obtained here are matching with the mathematical formula given above.
# Standard Normal Distribution
#Initializing the parameters:mean and SD
mu,sigma=0,1
np.random.seed(seed=32)
s_stdnorm= np.random.normal(mu, sigma, 1000)
plt.subplots(figsize=(10,5))
plot=sns.distplot(pd.DataFrame(s_stdnorm)).set_title('Standard Normal Distribution with $\mu$=%.1f and $\sigma^2$=%.1f' %(mu,sigma))
fig=plot.get_figure()

2. Uniform Continuous Distribution
In case of uniform continuous distribution, which is also know as rectangular distribution, the probability associated with each data points within a fixed interval is equal.
The probability density function for uniform distribution is:


For example: In winter, a person can gain weight post Christmas anywhere between 1lb to 50lb. Each of the numbers between 1 to 50 are equally probable. So in this example, 
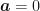



Properties of Uniform Distribution
- Mean and median of the distribution is given by
- Since the datapoints within the interval [a,b] are equally likely, so there is no skewness present in the distribution
- Variance of the distribution is given by


We will use the command np.random.uniform() to generate a random sample which follows rectangular distribution.
#Here parameters a and b has been assigned the values 1 and 6
s_uniform=np.random.uniform(1, 6, 500000)
np.random.seed(seed=32)
plt.subplots(figsize=(10,5))
plot=sns.distplot(pd.DataFrame(s_uniform)).set_title('Uniform Distribution with $a$=%.1f and $b$=%.1f'%(1,6))
fig=plot.get_figure()

The mean and variance of uniform distribution is calculated as
print(np.mean(s_uniform),np.var(s_uniform))
and the values we obtain are 3.49 (mean) and 2.08(variance). The values obtained here are matching with the mathematical formula given above.
3. Binomial Distribution
Binomial Distribution is a discrete probability distribution, which gives the sum of the outcomes obtained from n Bernoulli trials. For example, if a drug’s effect of curing a cancer is being tested on a patient, the result might be a success or a failure. The same experiment when conducted on 1000 cancer patients where n (trials) is large and we are interested to see exactly 5 successful cases, then the distribution becomes a binomial distribution. Here p measures drug’s success of curing cancer.
The probability density function of binomial distribution is:

The above equation is reduced to bernoulli distribution when n=k=1 and the equation becomes:

Properties of Binomial Distribution
- The probability of success is independent in each trial which implies the samples drawn randomly have been done with replacement
- Mean(
- Variance(
) of the distribution is given by
. The lower the variance of the distribution, the highly skewed will be the distribution. Skewness is given by
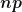

Relation between mean and variance:
- When p=0 then
=0 and
=0 which implies
- When p=1 then
- When 0
Since the third condition can be re-modeled as 
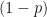
We will generate random sample which are binomially distributed using the command np.random.binomial().
#Initializing the parameters 'number of trials' and 'probaility of success'
n,p = 10,0.5
np.random.seed(seed=32)
s_binomial=np.random.binomial(n,p,1000)
plt.subplots(figsize=(10,5))
plot=sns.distplot(pd.DataFrame(s_binomial)).set_title('Binomial Distribution with $n$=%.1f,$p$=%.1f' % (n,p))
fig=plot.get_figure()

To get the mean and variance of a distribution, we will use the below code:
print(np.mean(s_binomial), np.var(s_binomial))
We find that mean is 5.036 and variance is 2.468 which proves that mean>variance in binomial. The values obtained here are matching with the mathematical formula given above.
4. Poisson Distribution
Poisson distribution is a discrete probability distribution which models number of times an event occurs in fixed time interval. It is a binomial approximated distribution which occurs when number of trials (
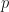

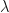
The probability density function of poisson distribution is:
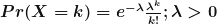
As an example: the number of file server virus infection at a data center during a 24-hour period is poisson distributed.
Properties of Poisson Distribution
- Probability of occurrence of one event is independent of the probability of occurrence of the other
- Mean (
) both are equal to
- Skewness is represented by
. The higher the constant term(
The command used to generate poisson distribution in python was np.random.poisson()
#Intializing the parameters for Poisson distribution
mean,k=2,100000
np.random.seed(seed=32)
s_poisson = np.random.poisson(mean,k)
plt.subplots(figsize=(10,5))
plot=sns.distplot(pd.DataFrame(s_poisson)).set_title('Poisson Distribution with $\lambda$=%.1f and $k$=%.1f'%(mean,k))
fig=plot.get_figure()

We can check the mean and variance of poisson distribution:
print(np.mean(s_poisson),np.var(s_poisson))
We will see that values 2.00 (mean) and 2.00 (variance) are very close value of
5. Gamma Distribution
Gamma distribution is a right skewed distribution used for continuous variables. This is due to its flexibility in the choice of the shape and scale parameters. The scale parameter determines where the bulk of the observations lies and the shape parameter determines how the distribution will look.
The probability density function of Gamma distribution:

Here 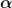


For example, to estimate rainfall for a location at select time interval, based on past data of the same, gamma distribution is a popular choice because of the flexibility in parameters: shape and scale.
Properties of Gamma Distribution
- Mean of the distribution is given by
- Variance of the distribution is given by
- Skewness is given by
. The lesser the shape parameter, the more skewed the distribution will be


We will use the command np.random.gamma() to generate random samples which follows gamma distribution.
#Initializing the parameters for Gamma distribution
shape, scale = 1, 2.
plt.subplots(figsize=(10,5))
np.random.seed(seed=32)
s_gamma = np.random.gamma(shape, scale, 50000)
plot=sns.distplot(pd.DataFrame(s_gamma)).set_title('Gamma Distribution with $shape$=%.1f and $scale$=%.1f'%(shape,scale))
fig=plot.get_figure()

We will compute the mean and variance by :
print(np.mean(s_gamma),np.var(s_gamma))
and the values we obtain are 1.994(mean) and 3.959(variance). The values obtained here are matching with the mathematical formula given above.
Below we will show how the change in each of the parameters 

Case1: Change in shape parameter with no change in scale parameter
s_gamma1=np.random.gamma(5,scale,5000)
np.random.seed(seed=32)
fig,(ax1,ax2)= plt.subplots(1,2, figsize=(15, 4))
plot=sns.distplot(pd.DataFrame(s_gamma),ax=ax1).set_title('Gamma Distribution with shape parameter =1')
fig=plot.get_figure()
plot1=sns.distplot(pd.DataFrame(s_gamma1),ax=ax2).set_title('Gamma Distribution with shape parameter =5')
fig1=plot1.get_figure()

It is clear from the above graph that with change in shape parameter, skewness of the distribution reduces.
Case2: Change in scale parameter with no change in shape parameter
s_gamma2=np.random.gamma(shape,5,5000)
np.random.seed(seed=32)
fig, (ax1,ax2) =plt.subplots(1,2,figsize=(15,4))
plot=sns.distplot(pd.DataFrame(s_gamma),ax=ax1).set_title('Gamma Distribution with scale parameter=2')
fig=plot.get_figure()
plot1=sns.distplot(pd.DataFrame(s_gamma2),ax=ax2).set_title('Gamma Distribution with scale parameter=5')
fig1=plot1.get_figure()

From the above figure, we can infer that with change in scale parameter, the tails of the distribution became more elongated with no change in skewness.
6. Tweedie Distribution
Tweedie distributions belongs to the family of linear exponential distributions with a dispersion parameter 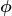
A variable Y is said to follow tweedie distribution if

Here 

In simple terms, the tweedie distribution can be explained as a sum of N independent gamma random variates where N follows a poisson distribution and N and gamma random variate are independent. In other words, for each poisson random variate, we are trying to find a corresponding gamma variate. For example, in case of modelling insurance claims, the number of incumbent claims can be modeled independently using poisson distribution as its a count(discrete) distribution and the severity(claim cost) associated with the claims can be modeled independently using gamma distribution as claim cost is continuous parameter, but when we look at them together then tweedie distribution views the situation as : “for a claim, it tries to find the product of poisson number of claims and gamma sized claim amount”. So if 5 claims have come, the tweedie will view these 5 claims as 5 claims with their associated claim cost.
However, the below code is focused on Poisson-Gamma distribution.
def tweedie(n,p,mu,phi):
np.random.seed(seed=32)
#checking the value of variance power between 1-2
if(p=2):
print('p must be between (1,2)')
pass
else:
rt=np.full(n,np.nan)
# calculating mean of poisson distribution
lambdaa=mu**(2-p)/(phi*(2-p))
# shape parameter of gamma distribution
alpha=(2-p)/(1-p)
# scale parameter of gamma distribution
gam= phi*(p-1)*(mu**(p-1))
# Generating Poisson random sample
N=np.random.poisson(lambdaa,n)
for i in range(n):
# Generate single data point of gamma distribution using poisson random variable
rt[i]=np.random.gamma(N[i]*np.abs(alpha),gam,1)
return(rt)
The above function has 4 parameters: n, p, mu, phi. Here 

Below we will see that how varying the constant parameter p between 1 and 2, the distribution moves from extreme poisson to extreme gamma distribution.
vals=[1.01,1.2,1.5,1.9]
fig, axes =plt.subplots(2,2, figsize=(15,6))
axes=axes.flatten()
for ax,i in zip(axes,vals):
s_tweedie=tweedie(50000,i,3,2)
sns.distplot(pd.DataFrame(s_tweedie),ax=ax).set_title('Tweedie Distribution with $p$=%.2f,$\mu$=%.1f and $\phi$=%.1f'%(i,3,2))
plt.tight_layout()
plt.show()

The values of
We show here the variance of tweedie with p=1.5, which is obtained using the command
print(np.var(s_tweedie))
The variance is 10.40 and the value obtained here is matching with the mathematical formula given above.
Sign off
There are various other distributions which can be looked for (listed here). I hope the above explanations helps the readers to have a good understanding about each of these distributions. This blog-post will help beginners in their data science journey as they will be able to identify, relate and differentiate among these distributions and apply these effectively in modeling data science problems.
If you liked the post, follow this blog to get updates about upcoming articles. Also, share it so that it can reach out to the readers who can actually gain from this. Please feel free to discuss anything regarding the post. I would love to hear feedback from you.
Happy learning distributions 🙂
Thats a lot number of distribution functions over there. And definitely a good resource for understanding distribution functions in numpy. Tweedie is a new one that I have come across.
Like