
In this blog-post, we will build a python program which performs Optical Character Recognition (OCR) and demonstrates to leverage it for solving real world business problems. Let us first understand the problem in brief. OCR refers to the technology which can process and convert the printed text from scanned images or documents into raw text which can be manipulated by machine.
In this blog-post, we will be walking through the following modules:
- Installing Tesseract OCR Engine.
- Running Tesseract with Command line.
- Running Tesseract with Python
- Running Parallel instances for Speed up
- Building the Pipeline for Real World Application.
You can download samples which are used in this blog-post from here.
1. Installing Tesseract OCR Engine
Tesseract is a popular open source project for OCR. You can visit the GitHub repository of Tesseract here. Much recently (in 2016), OCR developers had implemented LSTM based deep neural network (DNN) models (Tesseract 4.0) to perform OCR which is more accurate and faster than the previous conventional models.
Installing tesseract on windows is easy with the precompiled binaries found here. You can download and install the beta version exe from the Mannheim University Library page. Do not forget to edit “path” environment variable and add tesseract path.
2. Running Tesseract: Command Line
<
p style=”text-align: justify;”>You can see the converted text on command line by typing the following:
tesseract image_path stdoud
To write the output text in a file:
tesseract image_path result.txt
To specify the language model name, by default it takes english:
tesseract image_path result.txt -l eng
There are various page segmentation modes as a parameter. It directs the layout analysis that Tesseract performs on the page. There are 14 modes available which can be found here. By default, Tesseract fully automates the page segmentation, but does not perform orientation and script detection. To specify the parameter, type the following:
tesseract image_path result.txt -l eng --psm 6
Below is an example of scanned bill receipt of a restaurant on which OCR is performed.

The generated text after OCR is shown below:
Ying Thai Kitchen 2220 Queen Anne AVE N Seattle WA 98109 Tel. Fax. www. yingthaikitchen.com Welcome to Ying Thai Kitchen Restaurant, Order#:17 Table 2 Date: 7/4/2013 7:28 PM ~ Server: Jack (T.4) 44 Ginger Lover $9.50 [Pork] [2**] Brown Rice $2.00 Total 2 item(s) $11.50 Sales Tax $1.09 Grand Total $12.59 Tip Guide 15%=$1.89, 18%=$2.27, 20%=$2.52 , Thank you very much. Come back again
To OCR multiple pages in one run of Tesseract. Prepare a text file (savedlist.txt) that has the path to each image:
path/to/1.png
path/to/2.png
path/to/3.tiff
Save it, and then give its name as input file to Tesseract. “output.txt” will contain text generated from all the files in the list demarcated by page separator character.
tesseract savedlist.txt output.txt
3. Running Tesseract : Python
There are few wrappers built on the top of tesseract library in python. Python-tesseract (pytesseract) is a python wrapper for Google’s Tesseract-OCR. Type pip command to install the wrapper.
pip install pytesseract
Once you install the wrapper package, you are ready to write python codes for performing OCR. Just note that pytesseract is only a wrapper to access the methods of tesseract and still requires tesseract to be installed in system. We will write a simple python definition def ocr(img_path) to perform OCR. It takes an image path as input, performs OCR, writes the generated text to a .txt file and returns the output file name.
import pytesseract
import cv2
import re
def ocr(img_path):
out_dir = "ocr_results//"
img = cv2.imread(img_path)
text = pytesseract.image_to_string(img,lang='eng',config='--psm 6')
out_file = re.sub(".png",".txt",img_path.split("\\")[-1])
out_path = out_dir + out_file
fd = open(out_path,"w")
fd.write("%s" %text)
return out_file
4. Running Parallel instances for Speed up
In the previous section, we defined a function which takes an input image path and converts it into readable text. An obvious question of scale comes in when we have to process large number of images for example 1 million images. Thinking of that, I am penning down some of the ideas which one can try.
- Multi-Threading : If the system has 4 physical cores, one can run 4 parallel instances of tesseract and thus performing OCR of 4 images in parallel.
- Multi-page Feature : Multi-page feature of tesseract is much faster than single image conversion sequentially. To speed up the process, one should make a list of image paths and feed it to tesseract.
- Using SSDs or RAM as Disk : If there are large number of images, it can help in saving lot of I/O time. SSDs will have faster access and loading time.
- Running in Distributed system : Use MPI for python on a distributed system and scale it as much as you want. It is different than multi-threading as it is not limited to number of cores of a single system. You may have to bear more cost in terms of hardware.
Basically, In a multi-threading setup, a single server of 15-20 cores with SSD storage could process 1 million images in a day. A lot depends on implementation though. Below is an easy implementation to run multiple instances of tesseract in parallel over all the cores of the system using concurrent.futures library.
import os
import glob
import concurrent.futures
import time
os.environ['OMP_THREAD_LIMIT'] = '1'
def main():
path = "test"
if os.path.isdir(path) == 1:
out_dir = "ocr_results//"
if not os.path.exists(out_dir):
os.makedirs(out_dir)
with concurrent.futures.ProcessPoolExecutor(max_workers=4) as executor:
image_list = glob.glob(path+"\\*.png")
for img_path,out_file in zip(image_list,executor.map(ocr,image_list)):
print(img_path.split("\\")[-1],',',out_file,', processed')
if __name__ == '__main__':
start = time.time()
main()
end = time.time()
print(end-start)
We call map function of ProcessPoolExecutor class which takes a definition and the list of images as an input. It distributes the list of image paths and executes the passed definition on each core in parallel.
5. Building the Pipeline for Real World Application.
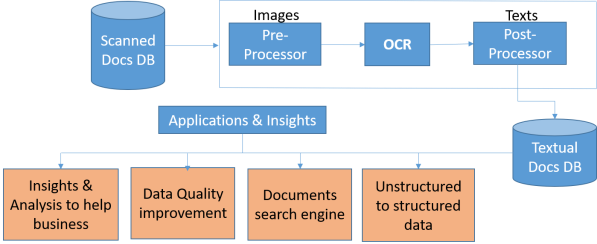
The Architecture of the ICR system consists of the 4 main components. They are shown below in sequence:
1. Image Corrector:
- The idea is to prepare the input image in order to do better text recognition in OCR component.
- Rectification of Image (Image Correction)
- Removal of borders from image.
- Text Segmentation & background cleaning.
- Use of OpenCV and Image Processing tools like ImageMagick
2. Optical Character Recognizer
- Implementation of State-of-the-art technique used in OCR.
- Using open source model : Tesseract.
- It is DNN based on Long short term memory( LSTM) published in 2016.
- Training of Tesseract required : For recognizing new fonts or hand written texts.
3. Text Processor & Corrector
- Implementation of spell-checker to further improve accuracy.
- Generated text needs post-processing in order to extract important fields.
- Use of Regex and text processing libraries.
- if necessary, We may set up the layout of text.
4. Data Population & Insight Generation
- Extracted fields to be populated in Database (Unstructured to structured data).
- It will augment the features/variables and improve the data quality.
- Insight generation to help business.
- Can be utilized for creating a documents exploration system.
A basic architecture of the end-to-end application is given below:
Important Note
There are few important things to keep in mind while building an tesseract based OCR application for solving some business problem.
- The standard format of input image for tesseract is “.tiff” or “.png”. It will be convert all formats to “.tiff”.
- Tesseract OCR works best with high-resolution images. It is recommended to convert all images to 300 DPI (Use ImageMagick).
- By default, Tesseract uses 4 threads for OCR. It’s better to set thread=1 for a single image as it reduces overheads. Further one can run multiple instances.
- OCR accuracy is affected by borders and lines in the images. Also background cleaning is required for better results. If you are not getting good results with tesseract, you may like to improve image quality (look for Fred’s Textcleaner script).
At the End
Hope it was a convenient read for all of you. I would encourage readers to reproduce the results demonstrated in the blog-post with python scripts. There is still a lot to explore in tesseract. Further, one can look for:
- To detect the layout of texts in images using the bounding boxes and its confidence probability. You can look for the other functions which gives such finer details for OCR.
- To train tesseract for new text fonts through transfer learning on LSTM models in order to improve accuracy.
- To understand LSTM based tesseract models and train it from scratch in order to perform handwritten text recognition.
To showcase the end-to-end application, I developed a basic QT desktop application. The below video demonstrates the idea.
Update: Readers can download the backup of QT application built from below link. It was a old work and don’t have a working app now. You may have to figure out codes in order to reproduce it. Good luck with that.
If you liked the post, follow this blog to get updates about the upcoming articles. Also, share this article so that it can reach out to the readers who can gain from this. Please feel free to discuss anything regarding solving such business problems.
Happy machine learning 🙂
Hi, I am stuck in a similar problem. I am doing ocr on a pdf of scanned images by taking out separate images from pdf and running tesseract 4.0 with pytesseract and flask. Also, i have used ‘threaded=True’ in flask to call tesseract from 2 systems, while the application is running on same server.
Now the problem is at a time, only one instance of tesseract runs to process first image of the first pdf and then it switches to process first image of second pdf. So, earlier it was taking 70sec to process all images of one file, now it is giving output after 140sec for both files.
Is there is way to run 2 instance of tesseract parallel and get output in 70sec for both files.
Please reply as soon as you can.
Thanks.
Liked by 1 person
I did not get that.
Why can not you run tesseract in parallel in backend as I have used here with concurrent library ?
Just check the codes here in blog. It run in parallel on number of cores you have in a system.
Like
Hi ,I installed tesseract 4.0 on windows machine.The OCR detection is good ,but the average execution time is around 1.5 sec per image which is too slow.I tried multi threading as per your code its not improving the speed.Can you please suggest to improve the speed of tesseract 4.0
Like
How did you manage to run multiple instances of Tesseract 4.x on a single machine? The Tesseract github repo as several issues like this:
https://github.com/tesseract-ocr/tesseract/issues/1019
https://github.com/tesseract-ocr/tesseract/issues/984
https://github.com/tesseract-ocr/tesseract/issues/2312
Liked by 1 person
Yes, I managed to run multiple instances and get speed up too with tesseract 4.0.
os.environ[‘OMP_THREAD_LIMIT’] = ‘1’
The above code limits the number of thread which tesseract invokes by default as 4. Limiting it to 1 allows you to simply run parallel instances of tesseract on number of cores available in your system.
Like
What base OS where you using for this? The only OS I’ve seen Tesseract capable of running multiple instances is OSX. On Ubuntu or any other Linux variant, running more than 1 Tesseract process on a single machine will deadlock.
https://github.com/tesseract-ocr/tesseract/issues/2312
https://github.com/tesseract-ocr/tesseract/issues/1019
https://github.com/tesseract-ocr/tesseract/issues/984
Like
Well, this particular application I developed in windows.
I did not find any dead lock issues though it took me sometime to figure out how to run parallel instances as tesseract itself invokes 4 threads whenever called.
Like
great post! where can we find the source code for the demo?
Like
Though late but I have updated the backup download link in “At the End” section.
Like
Hello,where can we find the source code for the demo?
Like
Hi Kumar,
Thank you for your post!
In the architecture of ICR system, you have mentioned about “Implementation of spell-checker to further improve accuracy”. Could you tell me about which technique you use here and the source code of it (GitHub link if possible)?
Best,
Si
Like
Hey,
In this blog-post. I have not used spell checker but yes definitely people use spell checker to improve mis-spelled words. Below are some good python spell checkers as PyPi packages. It would be a nice research though to find which one works best for your case.
1. autocorrect
2. pyspellchecker
Non-pythonic packages
1. https://github.com/bakwc/JamSpell
2. https://github.com/hunspell/hunspell
Let us know which one works well for you.
Also, Perter Norwig wrote a very nice article on how to write your own spelling corrector.
http://norvig.com/spell-correct.html
Like
Though very late but I have updated the backup download link in “At the End” section.
Like
Hi Kumar,
I’m having problems executing your provided snippets. Could you provide your full script? 🙂
Like
I have updated the backup download link in “At the End” section.
Like
Hi Kumar,
First of all, nice post.
I am getting this warnings:
OMP: Warning #96: Cannot form a team with 4 threads, using 1 instead.
OMP: Hint Consider unsetting KMP_DEVICE_THREAD_LIMIT (KMP_ALL_THREADS), KMP_TEAMS_THREAD_LIMIT, and OMP_THREAD_LIMIT (if any are set).
Is this expected to happen?
Like
Hi,
I don’t remember anything like that. Well, couple of things to say here.
– Development is done on windows. Check OS.
– Tesseract itself invokes 4 threads whenever called. To limit it to 1 thread, we use “os.environ[‘OMP_THREAD_LIMIT’] = ‘1’”
– Once single tesseract instance call is limited to 1 thread. We can run multiple instances in parallel.
Like
Many thanks, your code has speeded up my process nearly by factor 3. From 3.64s/File to 1.28s/File.
Like