
As in my previous post “Setting up Deep Learning in Windows : Installing Keras with Tensorflow-GPU”, I ran cifar-10.py, an object recognition task using shallow 3-layered convolution neural network (CNN) on CIFAR-10 image dataset. We achieved 76% accuracy.
In this blog-post, we will demonstrate how to achieve 90% accuracy in object recognition task on CIFAR-10 dataset with help of following concepts:
1. Deep Network Architecture
2. Data Augmentation
3. Regularization
CIFAR-10 Task – Object Recognition in Images
CIFAR-10 is an established computer-vision dataset used for object recognition. The CIFAR-10 data consists of 60,000 (32×32) color images in 10 classes, with 6000 images per class. There are 50,000 training images and 10,000 test images in the official data. The label classes in the dataset are:
- airplane
- automobile
- bird
- cat
- deer
- dog
- frog
- horse
- ship
- truck
The classes are completely mutually exclusive. It was collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. Let us visualize few of the images of test set using the python snippet given below.
from matplotlib import pyplot
from scipy.misc import toimage
from keras.datasets import cifar10
def show_imgs(X):
pyplot.figure(1)
k = 0
for i in range(0,4):
for j in range(0,4):
pyplot.subplot2grid((4,4),(i,j))
pyplot.imshow(toimage(X[k]))
k = k+1
# show the plot
pyplot.show()
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
show_imgs(x_test[:16])
The output plot would look like this:

1. Deep Neural Network Architecture
We saw previously that shallow architecture was able to achieve 76% accuracy only. So, the idea here is to build a deep neural architecture as opposed to shallow architecture which was not able to learn features of objects accurately.
The advantage of multiple layers is that they can learn features at various levels of abstraction. For example, if you train a deep CNN to classify images, you will find that the first layer will train itself to recognize very basic things like edges, the next layer will train itself to recognize collections of edges such as shapes, the next layer will train itself to recognize collections of shapes like wheels, legs, tails, faces and the next layer will learn even higher-order features like objects (truck, ships, dog, frog etc). Multiple layers are much better at generalizing because they learn all the intermediate features between the raw input and the high-level classification. At the same time, there are few important aspects which need to be taken care off to prevent over-fitting. Deep CNN are harder to train because:
a) Data requirement increases as the network becomes deeper.
b) Regularization becomes important as number of parameters (weights) increases in order to do learning of weights from memorization of features towards generalization of features.
Having said that we will build a 6 layered convolution neural network followed by flatten layer. The output layer is dense layer of 10 nodes (as there are 10 classes) with softmax activation. Here is a model summary:
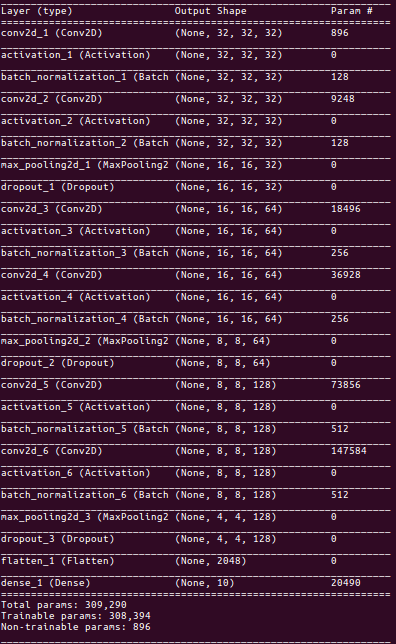
The process of building a Convolutional Neural Network majorly involves four major blocks show below.
Convolution layer ==> Pooling layer ==> Flattening layer ==> Dense/Output layer

Convolution layer is set of 3 operations: Convolution, Activation & Batch normalization. Sometimes, Dropout layer is kept after Pooling in lieu of regularization. Also, Multiple dense layer can be kept after flattening layer before finally keeping output dense layer. These are some general trends/norms which I have come across in designing CNN architectures.
2. Data Augmentation
In Keras, We have a ImageDataGenerator class that is used to generate batches of tensor image data with real-time data augmentation. The data will be looped over (in batches) indefinitely. The image data is generated by transforming the actual training images by rotation, crop, shifts, shear, zoom, flip, reflection, normalization etc. The below code snippets shows how to initialize the image data generator class.
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator( rotation_range=90,
width_shift_range=0.1, height_shift_range=0.1,
horizontal_flip=True)
datagen.fit(x_train)
To know more about all the possible arguments (transformations) and methods of this class, refer to Keras documentation here. For example, one can use flow(x, y) method that takes numpy data & label arrays, and generates batches of augmented/normalized data. It yields batches indefinitely, in an infinite loop. Below is the python snippet for visualizing the images generated using flow method of ImageDataGenerator class.
from matplotlib import pyplot as plt
# Configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(x_train, y_train, batch_size=9):
# Show 9 images
for i in range(0, 9):
plt.subplot(330 + 1 + i)
plt.imshow(toimage(X_batch[i].reshape(img_rows, img_cols, 3)))
# show the plot
plt.show()
break

If you want to get more insight or visualization on “Data Augmentation” by image generation in Keras, you may like to read blog-posts here and here.
3. Regularization
Deep neural nets with a large number of parameters are very powerful machine learning systems. However, overfitting is a serious problem in such networks. Given below are few techniques which were proposed recently and has become a general norm these days in convolutional neural networks.
Dropout is a technique for addressing this problem. The key idea is to randomly drop units (along with their connections) from the neural network during training. The reduction in number of parameters in each step of training has effect of regularization. Dropout has shown improvements in the performance of neural networks on supervised learning tasks in vision, speech recognition, document classification and computational biology, obtaining state-of-the-art results on many benchmark data sets [1].
Kernel_regularizer allows to apply penalties on layer parameters during optimization. These penalties are incorporated in the loss function that the network optimizes. This argument in convolutional layer is nothing but L2 regularisation of the weights. This penalizes peaky weights and makes sure that all the inputs are considered. During gradient descent parameter update, the above L2 regularization ultimately means that every weight is decayed linearly, that’s why called weight decay.
BatchNormalization normalizes the activation of the previous layer at each batch, i.e. applies a transformation that maintains the mean activation close to 0 and the activation standard deviation close to 1. It addresses the problem of internal covariate shift. It also acts as a regularizer, in some cases eliminating the need for Dropout. Batch Normalization achieves the same accuracy with fewer training steps thus speeding up the training process [2].
Having read a brief description of all the concepts that we are going to use here, Let’s look into full python implementation of object recognition task on CIFAR-10 dataset.
import keras
from keras.models import Sequential
from keras.utils import np_utils
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Dense, Activation, Flatten, Dropout, BatchNormalization
from keras.layers import Conv2D, MaxPooling2D
from keras.datasets import cifar10
from keras import regularizers
from keras.callbacks import LearningRateScheduler
import numpy as np
def lr_schedule(epoch):
lrate = 0.001
if epoch > 75:
lrate = 0.0005
if epoch > 100:
lrate = 0.0003
return lrate
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
#z-score
mean = np.mean(x_train,axis=(0,1,2,3))
std = np.std(x_train,axis=(0,1,2,3))
x_train = (x_train-mean)/(std+1e-7)
x_test = (x_test-mean)/(std+1e-7)
num_classes = 10
y_train = np_utils.to_categorical(y_train,num_classes)
y_test = np_utils.to_categorical(y_test,num_classes)
weight_decay = 1e-4
model = Sequential()
model.add(Conv2D(32, (3,3), padding='same', kernel_regularizer=regularizers.l2(weight_decay), input_shape=x_train.shape[1:]))
model.add(Activation('elu'))
model.add(BatchNormalization())
model.add(Conv2D(32, (3,3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('elu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3,3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('elu'))
model.add(BatchNormalization())
model.add(Conv2D(64, (3,3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('elu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.3))
model.add(Conv2D(128, (3,3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('elu'))
model.add(BatchNormalization())
model.add(Conv2D(128, (3,3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('elu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.4))
model.add(Flatten())
model.add(Dense(num_classes, activation='softmax'))
model.summary()
#data augmentation
datagen = ImageDataGenerator(
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
)
datagen.fit(x_train)
#training
batch_size = 64
opt_rms = keras.optimizers.rmsprop(lr=0.001,decay=1e-6)
model.compile(loss='categorical_crossentropy', optimizer=opt_rms, metrics=['accuracy'])
model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),\
steps_per_epoch=x_train.shape[0] // batch_size,epochs=125,\
verbose=1,validation_data=(x_test,y_test),callbacks=[LearningRateScheduler(lr_schedule)])
#save to disk
model_json = model.to_json()
with open('model.json', 'w') as json_file:
json_file.write(model_json)
model.save_weights('model.h5')
#testing
scores = model.evaluate(x_test, y_test, batch_size=128, verbose=1)
print('\nTest result: %.3f loss: %.3f' % (scores[1]*100,scores[0])
The output of above python implementation for object recognition task is shown below:

As you can see, the results on test-set reached approximately ~ 90%. One can fine tune it further and run it for more number of epochs to go past 90%.
More on Results
Let’s check out few images from test-set to find out the object class predicted by trained CNN. We will call the def show_imgs(X) method defined in first section “CIFAR-10 task – Object Recognition in Images” to display 16 images in 4*4 grid. Now, the trained CNN model is loaded into memory from disk and we predict object class of first 16 images from test-set.
Images must be Z-score (mean-std) normalized because that’s how we have implemented while training also. Z-score normalization is important because it results in similarly-ranged feature values and that the gradients don’t go out of control (need one global learning rate multiplier).
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# mean-std normalization
mean = np.mean(x_train,axis=(0,1,2,3))
std = np.std(x_train,axis=(0,1,2,3))
x_train = (x_train-mean)/(std+1e-7)
x_test = (x_test-mean)/(std+1e-7)
show_imgs(x_test[:16])
# Load trained CNN model
json_file = open('model.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
model = model_from_json(loaded_model_json)
model.load_weights('model.h5')
labels = ['airplane','automobile','bird','cat','deer','dog','frog','horse','ship','truck']
indices = np.argmax(model.predict(x_test[:16]),1)
print [labels[x] for x in indices]
References
[1] Dropout: A Simple Way to Prevent Neural Networks from Overfitting
[2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Concluding Remarks
Hope it was easy to go through tutorial as I have tried to keep it short and simple. Beginners who are interested in Convolutional Neural Networks can start with this application. In short, you have learnt how to implement following concepts with python and Keras.
-
- Plotting images with matplotlib.
- Z-score (mean-std normalization) of images.
- Building a deep Convolutional Neural Network.
- Applying batch normalization.
- Regularization : Dropout & Kernel regularizers.
- Data Augmentation : ImageDataGenerator in Keras.
- Saving & Loading DNN models (JSON format).
The full python implementation of object recognition task with ~90% accuracy on CIFAR-10 dataset can be found on Github link here.
If you liked the post, follow this blog to get updates about the upcoming articles. Also, share this article so that it can reach out to the readers who can actually gain from this. Please feel free to discuss anything regarding the post. I would love to hear feedback from you.
Happy deep learning 🙂
Abhijeet – Thanks for this post. I have a question regarding the training size. The Cifar 10 training size is 50,000 but I notice the training size as 791. I was under the assumption that after image augmentation the training size will be more than 50,000 – 50,000 from the original training pictures plus the ones that were augmented.
Like
It was a very helpful post! Thank you!
Is it ok to use your model on an implementation with AWS’s SageMaker?
Liked by 1 person
Feel free to use it anywhere
Like
Thank you!
Like
Hi Ravi,
The Image’s were processed batch by batch, not by each image. Here the batch size is 64, So dividing 50000/64 approx(781 steps for each epoch).
Like
HI,
it was great thanks,
but there is an issue because you used same validation and test data!
Like
The learning rate scheduler never enters the smallest rate of 0.0003 since it is an “elif” statement, so only if epoch100…. I think it should be an “if” statement instead?
Liked by 1 person
Thanks man !!
It should be if instead of elif. Updated!!
Like
Hi Abhijeet !!
Thanks for the code and its really helpful.
Can you please help me with how can I still increase the accuracy in the above program.
Also I tried this code with some modifications required for cifar100 dataset but got around 60% accuracy. How can i increase the accuracy.
Help needed.
Thanks in Advance!!
Regards,
Manohar N
Like
Need support
import keras
from keras import callbacks
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D, Activation
from keras.optimizers import SGD
from keras import backend as K
from keras.models import model_from_json
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = ‘retina’
plt.style.use(‘ggplot’)
from matplotlib import pyplot
from scipy.misc import toimage
def show_imgs(X):
pyplot.figure(1)
k = 0
for i in range(0,4):
for j in range(0,4):
pyplot.subplot2grid((4,4),(i,j))
pyplot.imshow(toimage(X[k]))
k = k+1
# show the plot
pyplot.show()
batch_size = 128
num_classes = 10
epochs = 2
img_rows, img_cols = 32, 32
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
if K.image_data_format() == ‘channels_first’:
x_train = x_train.reshape(x_train.shape[0], 3, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 3, img_rows, img_cols)
input_shape = (3, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 3)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 3)
input_shape = (img_rows, img_cols, 3)
x_train = x_train.astype(‘float32’)
x_test = x_test.astype(‘float32’)
x_train /= 255
x_test /= 255
print(‘x_train shape:’, x_train.shape)
print(x_train.shape[0], ‘train samples’)
print(x_test.shape[0], ‘test samples’)
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# Lenet
model = Sequential()
# first set of CONV => RELU => POOL
model.add(Conv2D(6, kernel_size=(5,5), # 6 – Filters
strides=(1,1),
padding=’same’, # adds sufficient padding to the input so that the output has same dimension as input
input_shape=input_shape,
use_bias=True,
kernel_initializer=’glorot_uniform’,
bias_initializer=’zeros’))
model.add(Activation(‘relu’))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# second set of CONV => RELU => POOL
model.add(Conv2D(16, kernel_size=(5,5), # 16 – Filters
padding=’valid’))
model.add(Activation(‘relu’))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Conv2D(120, kernel_size=(5,5),
padding=’valid’))
model.add(Activation(‘relu’))
model.add(Flatten())
model.add(Dense(84))
# softmax classifier
model.add(Dense(num_classes))
model.add(Activation(‘softmax’))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=SGD(lr=0.01),
metrics=[‘accuracy’])
model_checkpoints = callbacks.ModelCheckpoint(“weights_{epoch:02d}_{val_loss:.2f}.h5”, monitor=’val_loss’,
verbose=1, save_best_only=True, save_weights_only=False, mode=’auto’, period=1)
model_log = model.fit(x_train, y_train,
batch_size=batch_size, # number of samples to be used for each gradient update
epochs=epochs, # number of iterations over the entire x_train data
validation_data=(x_test, y_test), # on which to evaluate loss and model metrics at the end of each epoch
callbacks=[model_checkpoints])
#save to disk
model_json = model.to_json()
with open(‘model1.json’, ‘w’) as json_file:
json_file.write(model_json)
model.save_weights(‘model1.h5’)
#testing
scores = model.evaluate(x_test, y_test, batch_size=128, verbose=1)
print(‘\nTest result: %.3f loss: %.3f’ % (scores[1]*100,scores[0]))
f, (ax1, ax2) = plt.subplots(1, 2,figsize=(15,5))
ax1.plot(model_log.history[‘acc’])
ax1.plot(model_log.history[‘val_acc’])
ax1.set_title(‘Accuracy (Higher Better)’)
ax1.set(xlabel=’Epoch’, ylabel=’Accuracy’)
ax1.legend([‘train’, ‘validation’], loc=’lower right’)
ax2.plot(model_log.history[‘loss’])
ax2.plot(model_log.history[‘val_loss’])
ax2.set_title(‘Loss (Lower Better)’)
ax2.set(xlabel=’Epoch’, ylabel=’Loss’)
ax2.legend([‘train’, ‘validation’], loc=’upper right’)
score = model.evaluate(x_test, y_test, verbose=0)
print(‘Test loss:’, score[0])
print(‘Test accuracy:’, score[1])
output = model.predict_classes(x_test)
print (output)
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.astype(‘float32’)
x_test = x_test.astype(‘float32’)
# mean-std normalization
mean = np.mean(x_train,axis=(0,1,2,3))
std = np.std(x_train,axis=(0,1,2,3))
x_train = (x_train-mean)/(std+1e-7)
x_test = (x_test-mean)/(std+1e-7)
show_imgs(x_test[:16])
with open(‘model1.json’,’r’) as f:
model.load_weights(“model1.h5”)
# Load trained CNN model
#json_file = open(‘model.json’, ‘r’)
#loaded_model_json = json_file.read()
#json_file.close()
json = f.read()
model = model_from_json(json)
#model = model_from_json(loaded_model_json)
#model.load_weights(‘model.h5’)
labels = [‘airplane’,’automobile’,’bird’,’cat’,’deer’,’dog’,’frog’,’horse’,’ship’,’truck’]
indices = np.argmax(model.predict(x_test[:16]),1)
print ([labels[x] for x in indices])
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
ind = np.where(np.equal(output, y_test)==0)
output = model.predict_classes(x_test)
print (output)
err_x = x_test[ind[0]]
err_y = output[ind[0]]
print (err_x.shape)
//—————————————————————————
//MemoryError Traceback (most recent call last)
// in ()
//—-> 1 err_x = x_test[ind[0]]
// 2 err_y = output[ind[0]]
// 3 print (err_x.shape)
//MemoryError:
examples_per_class = 3
classes = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
for cls, cls_name in enumerate(classes):
idxs = np.where(cls == err_y)
idxs = np.random.choice(idxs[0], examples_per_class, replace=False)
for i, idx in enumerate(idxs):
plt.subplot(examples_per_class, len(classes), i * len(classes) + cls + 1)
plt.imshow(err_x[idx].astype(‘uint8’), cmap = ‘color’)
plt.axis(‘off’)
if i == 0:
plt.title(cls_name)
Liked by 2 people
Hello, you have really great work I really appreciate your sharing. I have a question how can I select 1000 images for each class instead of 10 000. I need to train the program for 1000 images and test it in 1000 test images too.
Like
Hello, you have really great work and I really appreciate the sharing. Can you please tell me how can I load 1000 training and testing images instead of 10 000 of each class?
Like
You can randomly sample from x_train and x_test.
Liked by 1 person
Thank you very much. I’ve tried:
x_train = x_train[1:1000]
x_test = x_test[1:1000]
y_train = y_train[1:1000]
y_test = y_test[1:1000]
and started worked but Im not sure if it is correct this way ?!
Also I’m trying to solve the mathematical mode of finding the weights from the parameters but I cant how it works by your program. Im new to machine learning and python.
Best regards.
Like
Using binary cross entropy for your loss function actually tricks keras into incorrectly determining the accuracy.
Like
Nice article keep posting … thanks
Like
Glad you liked !!
Like
Please ABHIJEET KUMAR, Can you Help me?
How can build CNN for Cifar10 in Pycharm step by step.
I need your help
I have tried before but I faced some problems like this when i tried to run the code in pycharm
(
Warning (from warnings module): File “C:\Program Files\Python37\lib\site-packages\keras\callbacks\callbacks.py”, line 95
% (hook_name, delta_t_median), RuntimeWarning) RuntimeWarning: Method (on_train_batch_end) is slow compared to the batch update (0.893450). Check your callbacks.)
Like
Hi I created a model using this method. It has only 3 classes and mAP is 0.981567. But when I test the model for untrained data sometimes it shows bounding box for other objects too. do u have any opinion on this? is having 98% accuracy level normal? do you think it happens because of the quality of the test data?
Like
I want faced this code lines when implement the code (
Warning (from warnings module): File “C:\Program Files\Python37\lib\site-packages\keras\callbacks\callbacks.py”, line 95
% (hook_name, delta_t_median), RuntimeWarning) RuntimeWarning: Method (on_train_batch_end) is slow compared to the batch update (0.893450). Check your callbacks.)
Please, what this mean?
I need your help
Like
Hi
It’s a great article.
It’s very interesting to read more about how AI can be used in the industry.
You would love to see my artificial intelligence course in delhi site as well.
Thanks once again.
Like
Hi
It’s a nice article.
It’s very interesting to read more about how AI can be used in the industry.
You would love to see my artificial intelligence online course site as well.
Thanks for sharing.
Like