
Keystroke dynamics is the study of the typing patterns of people to distinguish them from one another, based on of these patterns. Every user has a certain way of typing that separates him from other users; for example, for how long does a user press the keys, how much time between consecutive key presses, etc. Keystrokes are an upcoming area of research in biometrics. One famous application is the Coursera website using a typing test as the method to verify the students. No additional hardware is required to collect keystrokes; only a keyboard. Keystroke dynamics, together with security measures already in place (eg, password) can hence serve as a convenient 2-factor authentication.
In this post, we will verify the identity of users on the basis of their keystroke information. A model will be first trained by providing it with the typing patterns of the users to be enrolled, multiple patterns per user. The model is then provided with test patterns from the user as well as others posing as that user. The model should be able to reject the imposters while accept the genuine user based on the test pattern’s similarity to the trained model for the user. We will test various detectors which provide different ways of measuring this similarity.
The training and testing data for this post is the CMU Keystroke Dynamics Benchmark Data set, available for download here. It contains the keystroke information for 51 users, each user typing the password “.tie5Roanl” 400 times. The data has been collected over several sessions with at least a day’s gap between the sessions, so that any day-to-day variations between the user’s typing can be captured. Thus, the things we now need to understand are:
- What are the keystroke features being used?
- How is the model getting trained?
- Performance evaluation by various detectors.
1) What are the keystroke features being used?
The 3 most widely used features for keystroke dynamics are:
- Hold time – time between press and release of a key.
- Keydown-Keydown time – time between the pressing of consecutive keys.
- Keyup-Keydown time – time between the release of one key and the press of next key.
The CMU keystroke data-set provides us with these three features. The below picture depicts the three time periods used as features in keystroke data-set.

Lets see how to interpret the values given in the dataset. Given below is a row from the .csv file in the dataset.
subject sessionIndex rep H.period DD.period.t UD.period.t ....
s002 1 1 0.1491 0.3979 0.2488 ....
These feature vector contains the data for subject s002 (user) from his first session and first repetition in that session. The feature H.key tells the hold time for the key; eg, H.period is the hold time for the dot key. DD.key1.key2 is the keydown-keydown time for the key pair key1 and key2; eg, DD.period.t is the keydown-keydown time for pressing the dot key and the t key. Lastly, UD.key1.key2 is the keyup-keydown time for the keys key1 and key2; eg, UD.period.t is the keyup-keydown time for the dot key and t key.
The columns 4-34 thus have these time information for the various keys and key pairs in .tie5Roanl. There are 8 sessions per user and 50 repetitions per session, hence 400 keystroke vectors for one user.
The Python module pandas has been used to load the keystroke.csv file. The data variable is a panda data frame and contains the entire contents of the .csv file. subjects array has the labels of all the 51 subjects.
import pandas import numpy as np path = "D:\\Keystroke\\keystroke.csv" data = pandas.read_csv(path) subjects = data["subject"].unique()
2) How is the model getting trained?
From the 400 vectors (repeatitions of password) available for every user, we employ the first 200 for training the model for the user, to capture the his typing behaviour. trainvariable (a panda data frame) contains the training data.
We will be presenting the results on 5 different learning models.
- Manhattan Distance
- Manhattan Filtered Distance
- Manhattan Scaled Distance
- Gaussian Mixture Model (GMM)
- Support Vector Machines (SVM)
Our first detector is Manhattan Detector (MD). The training() function in the below Python code calculates the mean_vector for each user from the samples in train(training set). Here, only the mean of feature vectors is considered as user model.
Class ManhattanDetector:
def evaluate(self):
for subject in subjects:
genuine_user_data = data.loc[data.subject == subject,
"H.period":"H.Return"]
self.train = genuine_user_data[:200]
self.training()
def training(self):
self.mean_vector = self.train.mean().values
3) Performance evaluation
We will now supply the model of a user with unseen test sample as explained here- a test_genuine list which has the remaining 200 feature vectors (repetitions of password) of the same user and a test_imposter list which has 5 vectors each from all the other 50 users, making a total of 250 imposter samples. In total, each user will be tested 450 times for user’s authenticity. Again, keep in mind that this process will be repeated for all the 51 users.
#genuine samples - remaining 200 from 400
self.test_genuine = genuine_user_data[200:]
#imposter samples
imposter_data = data.loc[data.subject != subject, :]
self.test_imposter = imposter_data.groupby("subject").head(5).loc[:,
"H.period":"H.Return"]
Code snippet for the testing() function is shown below.
def testing(self):
for i in range(self.test_genuine.shape[0]):
cur_score = cityblock(self.test_genuine.iloc[i].values,
self.mean_vector)
self.user_scores.append(cur_score)
for i in range(self.test_imposter.shape[0]):
cur_score = cityblock(self.test_imposter.iloc[i].values,
self.mean_vector)
self.imposter_scores.append(cur_score)
Thus, the detector calculates the city block distance (Manhattan distance) between the test samples and mean_vector for the subject. Its easy to understand that smaller values of this distance indicate higher similarity of the sample to the subject’s model; however if the score has a larger value, it means the sample is quite dissimilar to the model and should get not get verified as the subject.
Having obtained the scores for both kind of samples, genuine and imposter, in lists user_scores and imposter_scores respectively, we evaluate the equal error rate (EER) for the detector.
eers = [] eers.append(evaluateEER(self.user_scores, self.imposter_scores))
The evaluateEER() function used above is shown in the snippet below.
#EER.py
#Put in a separate file in same folder, since all detectors import it.
def evaluateEER(user_scores, imposter_scores):
labels = [0]*len(user_scores) + [1]*len(imposter_scores)
fpr, tpr, thresholds = roc_curve(labels, user_scores + imposter_scores)
missrates = 1 - tpr
farates = fpr
dists = missrates - farates
idx1 = np.argmin(dists[dists >= 0])
idx2 = np.argmax(dists[dists < 0])
x = [missrates[idx1], farates[idx1]]
y = [missrates[idx2], farates[idx2]]
a = ( x[0] - x[1] ) / ( y[1] - x[1] - y[0] + x[0] )
eer = x[0] + a * ( y[0] - x[0] )
return eer
We report the average EER as the performance metric for the detectors.
average EER for Manhattan detector: 0.18065830919103248
Lets see the workflow of this detector in the full code below.
#Keystroke_Manhattan.py
from scipy.spatial.distance import cityblock
import numpy as np
np.set_printoptions(suppress = True)
import pandas
from EER import evaluateEER
class ManhattanDetector:
def __init__(self, subjects):
self.user_scores = []
self.imposter_scores = []
self.mean_vector = []
self.subjects = subjects
def training(self):
self.mean_vector = self.train.mean().values
def testing(self):
for i in range(self.test_genuine.shape[0]):
cur_score = cityblock(self.test_genuine.iloc[i].values, \
self.mean_vector)
self.user_scores.append(cur_score)
for i in range(self.test_imposter.shape[0]):
cur_score = cityblock(self.test_imposter.iloc[i].values, \
self.mean_vector)
self.imposter_scores.append(cur_score)
def evaluate(self):
eers = []
for subject in subjects:
genuine_user_data = data.loc[data.subject == subject, \
"H.period":"H.Return"]
imposter_data = data.loc[data.subject != subject, :]
self.train = genuine_user_data[:200]
self.test_genuine = genuine_user_data[200:]
self.test_imposter = imposter_data.groupby("subject"). \
head(5).loc[:, "H.period":"H.Return"]
self.training()
self.testing()
eers.append(evaluateEER(self.user_scores, \
self.imposter_scores))
return np.mean(eers)
path = "D:\\Keystroke\\keystroke.csv"
data = pandas.read_csv(path)
subjects = data["subject"].unique()
print "average EER for Manhattan detector:"
print(ManhattanDetector(subjects).evaluate())
We create a ManhattanDetector object with subjects array, and call its evaluate()function to kickstart the process.
4) Various types of other Detectors
Lets look at a few more detectors for our purpose and try to understand how differently they perform the training and the testing. First, we have slight variations of our simplistic Manhattan detector.
4.1) Manhattan Filtered Detector (MFD)
The training() function of the MFD takes into account any outliers in a subject’s typing habits. Such deviations from his/her usual typing habits may occur due to a variety of reasons, like the user being tired or bored and hence typing exceptionally slower than normal, etc. MFD simply filters (removes) such outliers.
#Keystroke_ManhattanFiltered.py
from scipy.spatial.distance import euclidean
class ManhattanFilteredDetector:
#just the training() function changes, rest all remains same.
def training(self):
self.mean_vector = self.train.mean().values
self.std_vector = self.train.std().values
dropping_indices = []
for i in range(self.train.shape[0]):
cur_score = euclidean(self.train.iloc[i].values,
self.mean_vector)
if (cur_score > 3*self.std_vector).all() == True:
dropping_indices.append(i)
self.train = self.train.drop(self.train.index[dropping_indices])
self.mean_vector = self.train.mean().values
We calculate mean_vector and standard deviation vector, std_vector for the user from his training vectors. To reject the outliers, first the euclidean distance between each of the training vectors and mean_vector is determined. Then, any vector for whom this distance is greater than three times the std_vector is an outlier and is dropped from train. dropping_indices consists of the indices of all such outliers. Having eliminated all such training vectors from the set, mean_vector for the user is re-calculated from the remaining samples in train. This mean_vector is now the model for the user’s typing behavior.
With this detector, we get the following average EER.
average EER for Manhattan Filtered detector: 0.148487121188
4.2) Manhattan Scaled detector (MSD)
Following are the training()and testing()functions for MSD.
#Keystroke_ManhattanScaled.py
class ManhattanScaledDetector:
#training() and testing() change, rest all remains same.
def training(self):
#calculating mean absolute deviation deviation of each feature
self.mean_vector = self.train.mean().values
self.mad_vector = self.train.mad().values
def testing(self):
for i in range(self.test_genuine.shape[0]):
cur_score = 0
for j in range(len(self.mean_vector)):
cur_score = cur_score + \
abs(self.test_genuine.iloc[i].values[j] - \
self.mean_vector[j]) / self.mad_vector[j]
self.user_scores.append(cur_score)
for i in range(self.test_imposter.shape[0]):
cur_score = 0
for j in range(len(self.mean_vector)):
cur_score = cur_score + \
abs(self.test_imposter.iloc[i].values[j] - \
self.mean_vector[j]) / self.mad_vector[j]
self.imposter_scores.append(cur_score)
While training, we calculate the mean_vector()as well as the mad_vector() which has the mean absolute deviation (MAD) of each feature of the training data. In testing(), score for a test sample is being calculated as 
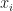

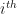
mean_vector()respectively, and 
mad_vector(). Thus, we are essentially calculating the city-block distance but each feature is getting scaled by its MAD. The resulting EER is:
average EER for Manhattan Scaled detector: 0.117636962313
Thus, in the detectors based on the Manhattan distance as the similarity score, we see that 
4.3) One-Class SVM
One class SVMs learn a decision function from the data of one class only and test a new sample to found out whether it is like the training data or not. This does exactly what we need, right? We will use sklearn.svm.OneClassSVM sub-module’s fit() function to train a OneClassSVM object, named clf here, and the decision_function() function to calculate the similarities scores for the test samples.
#Keystroke_SVM.py
from sklearn.SVM import OneClassSVM
class SVMDetector
#training() and testing() change, rest all remains same.
def training(self):
self.clf = OneClassSVM(kernel='rbf',gamma=26)
self.clf.fit(self.train)
def testing(self):
self.u_scores = -self.clf.decision_function(self.test_genuine)
self.i_scores = -self.clf.decision_function(self.test_imposter)
self.u_scores = list(self.u_scores)
self.i_scores = list(self.i_scores)
The EER was one class SVM was
average EER for One-class SVM detector : 0.12065079948315142
4.4) Gaussian Mixture Models
A digraph is a combination of 2 letters, like the password ‘.tie5Ronal’ has these digraphs – .t, ti, ie,…, na, al, . Our typing feature vector is essentially consisting of the various time latencies between the two letters of all the digraphs in the password. Now, GMMs can be used for determining whether a test typing vector belongs to one user or not since it has been proved in many studies that the digraph patterns present in keystroke data are generated by Gaussian distributions. Hence, we can model the user’s behaviour by fitting a GMM over the training data. The model is then used to calculate a test vector’s score which is its average log-likelihood of belonging to that model.
#keystroke_GMM.py
from sklearn.mixture import GMM
import warnings
warnings.filterwarnings("ignore")
class GMMDetector:
def training(self):
self.gmm = GMM(n_components = 2, covariance_type = 'diag',
verbose = False )
self.gmm.fit(self.train)
def testing(self):
for i in range(self.test_genuine.shape[0]):
j = self.test_genuine.iloc[i].values
cur_score = self.gmm.score(j)
self.user_scores.append(cur_score)
for i in range(self.test_imposter.shape[0]):
j = self.test_imposter.iloc[i].values
cur_score = self.gmm.score(j)
self.imposter_scores.append(cur_score)
The GMM object’s fit() and scores()are used to perform the above tasks, followed by calculating the EER, but with a different script (EER_GMM.py). For GMM detector, we calculated the false accept and false reject rates for the score thresholds between 20 and 51. For other detectors, the scores lied between the range 0 to 2, but for GMM, their range was from 20 to 51. The EER was obtained as:
average EER for GMM detector : 0.150204309173
The table below lists the EER for all the 5 detectors that we have employed:
| Detector | Average Equal Error Rate |
| Manhattan Detector | 0.18 |
| Manhattan Filtered Detector | 0.15 |
| Manhattan Scaled Detector | 0.12 |
| One Class SVM Detector | 0.12 |
| GMM Detector | 0.15 |
Concluding Remarks
Hope the blog-post helps in understanding how a user’s keystroke patterns are his representative and can be used for verifying him. Also, we hope that you are able to reproduce the results once you have followed the post till here. The objective of the blog-post was to introduce keystroke dynamics based authentication and present distance metric or scoring based machine learning models. More inquisitive ML enthusiasts can:
- Test various other detectors, like neural networks, Mahalanobis distance in place of Manhattan distance, etc, and compare their performance with the ones presented here.
- Find ways to capture their own keystroke information like one used in database and verify themselves with the system. We have not explored the ways to capture the keystroke events used in benchmark data-set.
The full implementation of followed approach and evaluation code for the test database can be downloaded from GitHub link here. All the presented models were combined in a single python file named “AllDetectors.py” (check github repo) using the inheritance concept.
The blog-post is partly an implementation of the following research paper.
Kevin S. Killourhy, Roy A. Maxion, “Comparing Anomaly-Detection Algorithms for Keystroke Dynamics“, IEEE conference on Dependable Systems & Networks, July, 2009.
Hope the blog-post provides a good hands-on and understanding of ML pipeline to our readers. If you liked the post, follow this blog to get updates about upcoming articles. Also, share it so that it can reach out to the readers who can actually gain from this. Please feel free to discuss anything regarding the post. I would love to hear feedback from you.
Happy machine learning 🙂
Hello, thanks a lot for explaining the python extension of GMM so well. However I have some doubts about the code in the GitHub link. If you could please tell me:
1. in the Keystroke_GMM.py file, why the number of components parameter in the GMM function is 2 (n_components) and
2. in the EER_GMM.py file, why the range value of the threshold variable is (20, 51) and how are you setting the size of the array matrix at the third line of the evaluateEERGMM function. I know you initialized one of the size parameter with the len(threshold) but why 3 after that?
Please if could clear the doubts, it will be generous of you. Thanks a lot again 🙂
Like
What is the full form of GMM?
Like