
There is a lot of information that can be extracted from a speech sample, for example, who is the speaker, what is the gender of the speaker, what is the language being spoken, with what emotion has the speaker spoken the sentence, the number of speakers in the conversation, etc. In the field of speech analytics with machine learning, gender detection is perhaps the most foundational task. This blog post is dedicated towards making foray into the field of speech processing with a Python implementation of gender detection from speech.
Data-sets: The below data-sets can be downloaded from here.
- Training corpus : It has been developed from YouTube videos and consists of 5 minutes of speech for each gender, spoken by 5 distinct male and 5 female speakers (i.e, 1 minute/speaker).
- Test corpus: It has been extracted from ““, a large scale manually annotated corpus recently released by Google this year (2017). The subset constructed from it contains 558 female only speech utterances and 546 male only speech utterances. All audio files are of 10 seconds duration and are sampled at 16000 Hz.
We will give a brief primer about how to work with speech signals. From the speech signals in training data, a popular speech feature, Mel Frequency Cepstrum Coefficients (MFCCs), will be extracted; they are known to contain gender information (among other things). The 2 gender models are built by using yet another famous ML technique – Gaussian Mixture Models (GMMs). A GMM will take as input the MFCCs of the training samples and will try to learn their distribution, which will be representative of the gender. Now, when the gender of a new voice sample is to be detected, first the MFCCs of the sample will be extracted and then the trained GMM models will be used to calculate the scores of the features for both the models. Model with the maximum score is predicted as gender of the test speech. Having given an overview of the approach, presented following is the organisation of this blog post:
- Working with speech frames
- Extracting MFCC features
- Training gender models using GMMs
- Evaluating performance on subset of AudioSet corpus
Lets begin!!
1. Working with speech frames
A speech signal is just a sequence of numbers which denote the amplitude of the speech spoken by the speaker. We need to understand 3 core concepts while working with speech signals:
-
Framing – Since speech is a non-stationary signal, its frequency contents are continuously changing with time. In order to do any sort of analysis of the signal, such as knowing its frequency contents for short time intervals (known as Short Term Fourier Transform of the signal), we need to be able to view it as a stationary signal. To achieve this stationarity, the speech signal is divided into short frames of duration 20 to 30 milliseconds, as the shape of our vocal tract can be assumed to be unvarying for such small intervals of time. Frames shorter than this duration won’t have enough samples to give a good estimate of the frequency components, while in longer frames the signal may change too much within the frame that the condition of stationary no more holds.
 A stationary signal
A stationary signal Speech, a non-stationary signal
Speech, a non-stationary signal -
Windowing – Extracting raw frames from a speech signal can lead to discontinuities towards the endpoints due to non-integer number of periods in the extracted waveform, which will then lead to an erroneous frequency representation (known as spectral leakage in signal processing lingo). This is prevented by multiplying a window function with the speech frame. A window function’s amplitude gradually falls to zero towards its two end and thus this multiplication minimizes the amplitude of the above mentioned discontinuities.
 Non integer number of periods
Non integer number of periods A windowed signal
A windowed signal - Overlapping frames – Due to windowing, we are actually losing the samples towards the beginning and the end of the frame; this too will lead to an incorrect frequency representation. To compensate for this loss, we take overlapping frames rather than disjoint frames, so that the samples lost from the end of the ith frame and the beginning of the (i+1)th frame are wholly included in the frame formed by the overlap between these 2 frames. The overlap between frames is generally taken to be of 10-15 ms.

2. Extracting MFCC features
Having extracted the speech frames, we now proceed to derive MFCC features for each speech frame. Speech is produced by humans by filtering applied by our vocal tract on the air expelled by our lungs. The properties of the source (lungs) are common for all speakers; it is the properties of the vocal tract, which is responsible for giving shape to the spectrum of signal and it varies across speakers. The shape of the vocal tract governs what sound is produced and the MFCCs best represent this shape.
MFCCs are mel-frequency cepstral coefficients which are some transformed values of signal in cepstral domain. From theory of speech production, speech is assumed to be convolution of source (air expelled from lungs) and filter (our vocal tract). The purpose here is to characterise the filter and remove the source part. In order to achieve this,
- We first transform the time domain speech signal into spectral domain signal using Fourier transform where source and filter part are now in multiplication.
- Take log of the transformed values so that source and filter are now additive in log spectral domain. Use of log to transform from multiplication to summation made it easy to separate source and filter using a linear filter.
- Finally, we apply discrete cosine transform (found to be more successful than FFT or I-FFT) of the log spectral signal to get MFCCs. Initially the idea was to transform the log spectral signal to time domain using Inverse-FFT but ‘log’ being a non-linear operation created new frequencies called Quefrency or say it transformed the log spectral signal into a new domain called cepstral domain (ceps being reverse of spec).
- The reason for the term ‘mel’ in MFFC is mel scale which exactly specifies how to space our frequency regions. Humans are much better at discerning small changes in pitch at low frequencies than they are at high frequencies. Incorporating this scale makes our features match more closely what humans hear.
The above explanation is just to give the readers an idea of how these features were motivated. If you really like to explore and understand more about MFCCs, you can read in this blog. You can find various implementation for extracting MFCCs on internet. We have employed python_speech_features (check here). All you have to do is pip install python_speech_features. One can also install scikits talkbox for the same. The following python code is a function to extract MFCC features from given audio.
import python_speech_features as mfcc
def get_MFCC(sr,audio):
features = mfcc.mfcc(audio, sr, 0.025, 0.01, 13, appendEnergy = False)
features = preprocessing.scale(features)
return features
3. Training gender models
In order to build a gender detection system from the above extracted features, we need to model both the genders. We employ GMMs for this task.
A Gaussian mixture model is a probabilistic clustering model for representing the presence of sub-populations within an overall population. The idea of training a GMM is to approximate the probability distribution of a class by a linear combination of ‘k’ Gaussian distributions/clusters, also called the components of the GMM. The likelihood of data points (feature vectors) for a model is given by following equation:

, where 
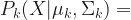

The training data 



Initially, it identifies k clusters in the data by the K-means algorithm and assigns equal weight 



from sklearn.mixture import GMM gmm = GMM(n_components = 8, n_iter = 200, covariance_type='diag',n_init = 3) gmm.fit(features)
Python’s sklearn.mixture package is used by us to learn a GMM from the features matrix containing the MFCC features. The GMM object requires the number of components n_components to be fitted on the data, the number of iterations n_iter to be performed for estimating the parameters of these n components, the type of co-variance covariance_type to be assumed between the features and the number of times n_ init the K-means initialization is to be done. The initialization which gave the best results is kept. The fit() function then estimates the model parameters using the EM algorithm.
The following Python code is used to train the gender models. The code is run once for each gender and source is given the path to the training files for the respective gender.
#train_models.py
import os
import cPickle
import numpy as np
from scipy.io.wavfile import read
from sklearn.mixture import GMM
import python_speech_features as mfcc
from sklearn import preprocessing
import warnings
warnings.filterwarnings("ignore")
def get_MFCC(sr,audio):
features = mfcc.mfcc(audio,sr, 0.025, 0.01, 13,appendEnergy = False)
features = preprocessing.scale(features)
return features
#path to training data
source = "D:\\pygender\\train_data\\youtube\\male\\"
#path to save trained model
dest = "D:\\pygender\\"
files = [os.path.join(source,f) for f in os.listdir(source) if
f.endswith('.wav')]
features = np.asarray(());
for f in files:
sr,audio = read(f)
vector = get_MFCC(sr,audio)
if features.size == 0:
features = vector
else:
features = np.vstack((features, vector))
gmm = GMM(n_components = 8, n_iter = 200, covariance_type='diag',
n_init = 3)
gmm.fit(features)
picklefile = f.split("\\")[-2].split(".wav")[0]+".gmm"
# model saved as male.gmm
cPickle.dump(gmm,open(dest + picklefile,'w'))
print 'modeling completed for gender:',picklefile
4. Evaluation on subset of AudioSet corpus
Upon arrival of a test voice sample for gender detection, we begin by extracting the MFCC features for it, with 25 ms frame size and 10 ms overlap between frames . Next we require the log likelihood scores for each frame of the sample, 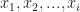

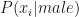
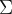
Similar to this, the likelihood of the speech being male is calculated by substituting the values of the parameters of the trained male GMM model and repeating the above procedure for all the frames. The Python code given below predicts the gender of the test audio.
#test_gender.py
import os
import cPickle
import numpy as np
from scipy.io.wavfile import read
import python_speech_features as mfcc
from sklearn import preprocessing
import warnings
warnings.filterwarnings("ignore")
def get_MFCC(sr,audio):
features = mfcc.mfcc(audio,sr, 0.025, 0.01, 13,appendEnergy = False)
feat = np.asarray(())
for i in range(features.shape[0]):
temp = features[i,:]
if np.isnan(np.min(temp)):
continue
else:
if feat.size == 0:
feat = temp
else:
feat = np.vstack((feat, temp))
features = feat;
features = preprocessing.scale(features)
return features
#path to test data
sourcepath = "D:\\pygender\\test_data\\AudioSet\\female_clips\\"
#path to saved models
modelpath = "D:\\pygender\\"
gmm_files = [os.path.join(modelpath,fname) for fname in
os.listdir(modelpath) if fname.endswith('.gmm')]
models = [cPickle.load(open(fname,'r')) for fname in gmm_files]
genders = [fname.split("\\")[-1].split(".gmm")[0] for fname
in gmm_files]
files = [os.path.join(sourcepath,f) for f in os.listdir(sourcepath)
if f.endswith(".wav")]
for f in files:
print f.split("\\")[-1]
sr, audio = read(f)
features = get_MFCC(sr,audio)
scores = None
log_likelihood = np.zeros(len(models))
for i in range(len(models)):
gmm = models[i] #checking with each model one by one
scores = np.array(gmm.score(features))
log_likelihood[i] = scores.sum()
winner = np.argmax(log_likelihood)
print "\tdetected as - ", genders[winner],"\n\tscores:female ",log_likelihood[0],",male ", log_likelihood[1],"\n"
Results
The following confusion matrix shows the results of the evaluation on the subset extracted from AudioSet corpus. The approach performs brilliantly for the female gender, with an accuracy of 95%, while for the male gender the accuracy is 76%. The overall accuracy of the system is 86%.
| male | female | |
| male | 417 | 129 |
| female | 29 | 529 |
If we look at the performance, trained female model seems to be good representative of their gender in comparison to trained male model. The possible reasons and areas of improvement has been discussed in next section. We also evaluated the same trained gender models on an exhibition data-set that consists of 250 audio files (130 males and 120 females) collected in a real-time environment during an open technology exhibition. The results of the evaluation on the exhibition data-set are shown in the following confusion matrix.
| male | female | |
| male | 115 | 15 |
| female | 1 | 119 |
Female gender model had an accuracy of 99%, while for the male gender the accuracy is 88%. The overall accuracy of the system is 94%.
Concluding Remarks
We hope the blog post was successful in explaining to you your first speech processing task. We expect you to reproduce the results posted by us. In order to get a better understanding of the various parameters used by us, you can play with them, for example:
- Train gender models on larger data-set. In the experiments performed, training data consists of 5 minutes of speech per gender only. A larger data-set may improve the accuracy as it will encompass the MFCCs well.
- Clean the extracted data-set from AudioSet. We have not done any cleaning or noise removal. Few of the audios are noisy and the spoken speech part in audio is less in the 10 seconds audio clip.
- Readers can study the effect of number of GMM components on the performance of the models.
- We have taken only MFCCs in order to build a gender detection system. In literature, you can find lot of acoustic features that are used to build gender model. For reference here is a link.
The full implementation of followed approach for training and evaluation of gender detection from voice can be downloaded from GitHub link here. Also remember to download the data-set provided at the beginning of blog-post.
If you liked the post, follow this blog to get updates about upcoming articles. Also, share it so that it can reach out to the readers who can actually gain from this. Please feel free to discuss anything regarding the post. I would love to hear feedback from you.
Happy machine learning 🙂
Good one
Liked by 1 person
Can we get a python 3 version of the same code ?
Like
We can get at https://github.com/AkashPatel1/Gender_Detect
Like
Sorry to spam! I tried converting the whole code to python3
Training of data set can be achieved with 2.7 ,
but i need the test_gender to work in 3.x , although i tried converting it to python 3 code , i get an error as
Traceback (most recent call last):
File “test.py”, line 81, in
models = [cPickle.load(open(fname,’r’)) for fname in gmm_files]
File “test.py”, line 81, in
models = [cPickle.load(open(fname,’r’)) for fname in gmm_files]
TypeError: a bytes-like object is required, not ‘str’
i tried to load the fname parameter with ‘rb’ mode , and also wrote them in ‘wb’ mode using the train_data.py , Still did not work!
Would be helpful if you could tell me where i went wrong 🙂
Like
replacing ‘r’ with ‘rb’ and ‘w’ with ‘wb’ worked for me, I think there is some other error after doing those changes
Like
change it to ‘rb’ in open(fname,’r’) it should be open(fname,’rb’)
Like
How to get the same in 3.7 using GausssianMixture function instead of GMM
Like
from sklearn.mixture import GaussianMixture as GMM
gmm = GMM(n_components=16, max_iter=200, covariance_type=’diag’, n_init=3)
Like
This program can be implimented in real time
Like
Why are we training our model only on male voice dataset. And if we have trained on male voice how can it identify the female voice?
Like
sir can you explain how log_likelihood[i] = scores.sum()
winner = np.argmax(log_likelihood)
is working.
Like
sir can u make blog on voice cloning system using TKinter or django or pytorch or tensorflow.
At which we can record our voice and it will mimic our voice as it is.
Like
Hii,
i’m using these code in python 3.8.2. the training code has running successfully but getting a error while running testing code. below is the error. plz someone help me.
C:/Python/python.exe e:/Python/gmm_1.py
–EQQVMYe50.wav
Traceback (most recent call last):
File “e:/Python/gmm_1.py”, line 49, in
winner = np.argmax(log_likelihood)
File “”, line 5, in argmax
File “C:\Python\lib\site-packages\numpy\core\fromnumeric.py”, line 1186, in argmax
return _wrapfunc(a, ‘argmax’, axis=axis, out=out)
File “C:\Python\lib\site-packages\numpy\core\fromnumeric.py”, line 61, in _wrapfunc
return bound(*args, **kwds)
ValueError: attempt to get argmax of an empty sequence
Like