
The Naive Bayes classifier is a frequently encountered term in the blog posts here; it has been used in the previous articles for building an email spam filter and for performing sentiment analysis on movie reviews. Thus a post explaining its working has been long overdue. Despite being a fairly simple classifier with oversimplified assumptions, it works quite well in numerous applications. Let us now try to unravel its working and understand what makes this family of classifiers so popular.
We begin by refreshing our understanding about the fundamental concepts behind the classifier – conditional probability and the Bayes’ theorem. This is followed by an elementary example to show the various calculations which are made to arrive at the classification output. Finally, we implement the classifier’s algorithm in Python and then validate the code’s output with results obtained for the demonstrated example.
Conditional Probability and Bayes’ Theorem
In the simplest terms, conditional probability, denoted as 






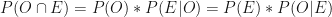
The equality of the two terms on the right leads to the Bayes’ Theorem.

Thus, the Bayes’ Theorem is a way to go from
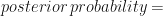
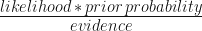
Why is it called “Naive”?
So far, we have only talked about the effect of a single event E on the occurrence of outcome O. In reality however, the probability of outcome O’s occurrence is governed by more than one already occurred event. The mathematics behind such a scenario gets very complicated and is made simple by assuming that the various governing events are independent of each other. Mathematically expressing, if an outcome O depends on events 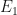


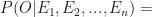


Thus, the model is very naively believing that the effect of the occurrence of any of the events is completely independent of the occurrence of other events. This is obviously not the case with most of the real world problems and the predictor features are known to influence and be influenced by other features. Still, naive Bayes is known to provide results at par and sometimes even better than highly complex and computationally expensive classification models.
An Illustrative Example
Lets clear our understanding by taking a simple example. Suppose we have the following training data (taken from YouTube video) regarding whether a patient had the flu or not, depending on if he had chills, a runny nose, headache and fever .

You might have guessed that chills, runny nose, headache and fever are features (analogous to the already occurred events 


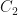



How to decide whether the patient has flu or not using the naive Bayes’ classifier?
How is the classification done?
For the task of classification, we use the training data to determine the prior probabilities of the 2 classes (flu or no flu) and the likelihoods of the 4 events that govern these outcomes. We begin by calculating the likelihoods of each of the event given the class, like 



The various probabilities that we are going to require as per equation 1 for the case when the patient has flu, ie, 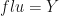
|
|
 |
() |
|
|
 |
( ) ) |
|
|
 |
(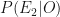 ) ) |
|
|
 |
( ) ) |
|
|
|
() |
|
|
 |
(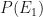 ) ) |
|
|
 |
(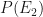 ) ) |
|
|
|
( ) ) |
|
|
|
( ) ) |









Now calculating 

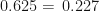
Similarly, the various probabilities are calculated for the case of 
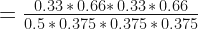
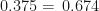
Thus the naive Bayes’ classifier will predict the class
If you notice, you can see what the task of prediction eventually reduces to – just calculating some probabilities and a few multiplications. All fairly easy and quick. If you pay even more attention, you see that since the denominator is the same while determining the probabilities of the outcome as either flu or no flu, you can even do away without calculating its value.
Thus



Again, the calculated probabilities give the same prediction as before, ie, no flu. We will validate these 2 values in the next section via a Python code.
This is what makes naive Bayes’ so popular as a classifier, combined with the fact that it has been seen to perform exceptionally well in many applications.
Python implementation
Lets cross check our values by writing a Python script for the above example.
Foremost, we build the training data from Figure 1. For the features, we provide label 1 to all Y (ie, the symptom was present in the patient) and 0 to all N (ie, the symptom was not present in the patient). Also, in the case of the feature “headache”, no headache = 0, mild = 1 and strong = 2. The outcome also follows the same pattern and thus, no flu = 0 and flu = 1.
import numpy as np
training = np.asarray(((1,0,1,1),
(1,1,0,0),
(1,0,2,1),
(0,1,1,1),
(0,0,0,0),
(0,1,2,1),
(0,1,2,0),
(1,1,1,1)));
outcome = np.asarray((0,1,1,1,0,1,0,1))
We begin by calculating the prior probabilities of the two classes. We use a dictionary for the same.
from collections import Counter, defaultdict
def occurrences(outcome):
no_of_examples = len(outcome)
prob = dict(Counter(outcome))
for key in prob.keys():
prob[key] = prob[key] / float(no_of_examples)
return prob
When we call occurrences(classes), we get the following prior probabilities for the 2 classes.
Prior probabilities = {0: 0.375, 1: 0.625}
Now we need to count the occurrences of the features class-wise. For this, we again employ a dictionary and separate the vectors of the 2 classes, by looking at a subset of the training set, taking one class at a time.
classes = np.unique(outcome)
rows, cols = np.shape(training)
likelihoods = {}
for cls in classes:
#initializing the dictionary
likelihoods[cls] = defaultdict(list)
for cls in classes:
#taking samples of only 1 class at a time
row_indices = np.where(outcome == cls)[0]
subset = training[row_indices, :]
r, c = np.shape(subset)
for j in range(0, c):
likelihoods[cls][j] += list(subset[:,j])
If you look at likelihoods when the code has run, it will look as follows:
{0: defaultdict(, {0: [1, 0, 0], 1: [0, 0, 1], 2: [1, 0, 2], 3: [1, 0, 0]}),
1: defaultdict(, {0: [1, 1, 0, 0, 1], 1: [1, 0, 1, 1, 1], 2: [0, 2, 1, 2, 1], 3: [0, 1, 1, 1, 1]})}
For both the classes 0 and 1, and for each of the 4 features, we have thus saved the occurrences in likelihoods. For example, for the class 0 (no flu), and feature 1 (ie, runny nose), the occurrences are 0, 0 and 1. Now what remains is to calculate the probabilities, per class, per feature.
for cls in classes:
for j in range(0,c):
likelihoods[cls][j] = occurrences(likelihoods[cls][j])
likelihoods will now contain the probabilities per feature per class.

The class of a previously unseen example will be determined by the following code.
results = {}
for cls in classes:
class_probability = class_probabilities[cls]
for i in range(0,len(new_sample)):
relative_feature_values = likelihoods[cls][i]
if new_sample[i] in relative_feature_values.keys():
class_probability *= relative_feature_values[new_sample[i]]
else:
class_probability *= 0
results[cls] = class_probability
For the test case in Figure 2, ie, new_sample = [1 0 1 0], we get
results = {0: 0.018518518518518517, 1: 0.006000000000000002}
, which are the same as we had calculated in theory.
The entire code is as follows:
import numpy as np
from collections import Counter, defaultdict
def occurrences(list1):
no_of_examples = len(list1)
prob = dict(Counter(list1))
for key in prob.keys():
prob[key] = prob[key] / float(no_of_examples)
return prob
def naive_bayes(training, outcome, new_sample):
classes = np.unique(outcome)
rows, cols = np.shape(training)
likelihoods = {}
for cls in classes:
likelihoods[cls] = defaultdict(list)
class_probabilities = occurrences(outcome)
for cls in classes:
row_indices = np.where(outcome == cls)[0]
subset = training[row_indices, :]
r, c = np.shape(subset)
for j in range(0,c):
likelihoods[cls][j] += list(subset[:,j])
for cls in classes:
for j in range(0,cols):
likelihoods[cls][j] = occurrences(likelihoods[cls][j])
results = {}
for cls in classes:
class_probability = class_probabilities[cls]
for i in range(0,len(new_sample)):
relative_values = likelihoods[cls][i]
if new_sample[i] in relative_values.keys():
class_probability *= relative_values[new_sample[i]]
else:
class_probability *= 0
results[cls] = class_probability
print results
if __name__ == "__main__":
training = np.asarray(((1,0,1,1),(1,1,0,0),(1,0,2,1),(0,1,1,1),(0,0,0,0),(0,1,2,1),(0,1,2,0),(1,1,1,1)));
outcome = np.asarray((0,1,1,1,0,1,0,1))
new_sample = np.asarray((1,0,1,0))
naive_bayes(training, outcome, new_sample)
Final Thoughts
Hope the bog-post was easy to follow and gives you a good understanding of Naive Bayes classifiers.
The naive Bayes (NB) classifier is a probabilistic classifier that assumes complete independence between the predictor features. They perform quite well even though the working behind them is simplistic. There exist other methods as well to determine the likelihoods of the features. Thus the NB classifiers are actually a family of classifiers rather being just a single classifier. Below are the classifiers available in any machine learning library, such as sklearn for Python.
- Gaussian NB – The likelihood of the features is assumed to be Gaussian distribution.
- Multinomial NB – This works for multinomially distributed data like word count vector where features in the vectors are probability of the event appearing in the sample.
- Bernoulli NB – This is used for multivariate Bernoulli distributions; i.e., there may be multiple features but each one is assumed to be a binary-valued (boolean) variable.
I will strongly recommend learners to read about the likelihood calculations of above variants in order to understand more practical usage of Naive Bayes classifier in various applications like sentiment analysis, email spam filters, etc.
If you liked the post, follow this blog to get updates about upcoming articles. Also, share it so that it can reach out to the readers who can actually gain from this. Please feel free to discuss anything regarding the post. I would love to hear feedback from you.
Happy machine learning 
Very helpful blog. Thank You.
Liked by 1 person
Your blog is very insightful in its explanation of the probability part of Naive Bayes, however, I have one question: shouldn’t P(flu=Y|E1, E2, E3, E4), and P(flu=N|E1, E2, E3, E4), add up to 1?
Like
Thanks Siddharth. Sum of posterior probability (class prob.) does not sum to 1 in Naive Bayes. Events itself can carry multiple values, So it all depends on what statistics and probability is in training data.
Example:
P(chills=y | flu=Y) and P(chills=y | flu=N) will not sum to 1. Try to figure it out and refer the table in Figure 1.
Like
While the illustration is very helpful, I think there is a flaw in the assumption of independence of events. The events are not simply independent of each other, rather they are conditionally independent on the outcome instance. Please note that, the occurrence of the first criteria, doesn’t imply the occurrence of the latter.
Liked by 1 person
Hi sayan,
Though I did not get your point completely but I would like to mention that whether the events are truly independent or not with each other, Naive Bayes assumes that they are independent, That’s why naive bayes are called naive.
Events are conditionally dependent on classes/outcomes. The probability of each event taken in account are considered independent of all other events.
Like
So, what Sayan was saying is that the events ‘may’ or ‘may not’ be independent of each other but, for given a outcome, they are assumed to be independent. In other words, it is conditional independence. The key word is ‘Conditional’.
There is a great example given by Tom Mitchell. Let’s consider three events – rain, thunder, and lightning. Since lightning causes thunder, once there’s a lightning, no additional information is required for the third event which is rain in this case. So, although there’s a definite dependence b/w rain and thunder in general, the dependency disappears in the presence of lightning i.e. they become conditionally independent with the presence of lightning.
This is a great example to understand conditional independence but don’t get into the details of this example – the example is flawed too but I’ll save the confusion. 🙂
Like
Nice post! Very instructive!
Liked by 1 person
such a difficult to understand please share some to be understandable.
Like
Awesome post. When to use the conditional probablity one you solved over the gaussian probablity to solve likelihood? In many place i could see that they are using gaussian.
Like
Conditional probabilities in naive bayes is calculated depending upon type of data distribution.
Mostly, if the data follows normal/gaussian distribution then gaussian probabilities are calculated.
In case of count data, you may like to use frequency based probabilities as show in this post.
In case the data follows gamma distribution, you may like to calculate probabilities based on Gamma distribution.
So you see, it all depends on data.
Like
The most complete, accurate and the best explanation of NB.
Like