One of the most frequently encountered task in many ML applications is classification. From the plethora of classifiers at our disposal, Support Vector Machines (SVM) are arguably the most widely used one. Yet, the intuition behind their working and the key concepts are seldom understood and their understanding is reduced to just learning a few buzzwords such as hyperplanes, kernels, support vectors, etc. This post is an attempt to unroll the mystery that SVMs tend to become for beginners in ML.
Introduction – Hyperplane and Margin
An SVM performs two class classification by building a classifier based on a training set, making it a supervised algorithm. The training set points have features and their class label. An SVM aims to find a separating boundary from which the distances of all the training points are as large as possible. This boundary is what is called the optimal hyperplane, while the distances give an idea about the margin. Notice the word optimal used with hyperplane – its easy to imagine that there will be a lot of boundaries that can separate the data points of the 2 classes, but the fact that SVM finds the one located as far as possible from the data points of either class makes it optimal. The figure below illustrates this important concept about SVMs.

The points plotted in the figure are feature vectors for 40 speech files belonging to 2 emotion classes – happy and sad (20 each). The feature vectors have been projected to a 2D space from their high dimensional space by applying principal component analysis (PCA) for visualization purposes. You may be having many questions after reading this – from where these data points are coming, why PCA has been used, what are the 2 axes, etc. Don’t worry too much. Just understand we have a dataset of points from 2 classes (happy and sad) which we want to separate. In the figure above, while the pink, cyan and brown lines are also separating the data points of these 2 classes, its the blue line which is the optimal separating hyperplane.
We move ahead by explaining the concept of margin. Margin is the distance between the optimal hyperplane and the training data point closest to the hyperplane. This distance, when taken on both the sides of the hyperplane, forms a region where no data point will ever lie. SVM intends to make this region as wide as possible and the selection of the optimal hyperplane is such that it aids in fulfilling this target.

If it were to choose a hyperplane which is quite close to any of the data point, the margin would have been small.

Thus, an SVM builds a classifier by searching for a separating hyperplane which is optimal and maximizes the margin.
Its time to delve into the mathematics behind the above keywords. Firstly, lets clear the air about what a hyperplane is. In the figures above, we saw our separating hyperplane to be a line. Then why did we call it a plane at all, moreover a hyperplane? In essence, a hyperplane is just a fancy word for a plane. It becomes a point for 1 dimensional data points, a line when data points are of 2 dimensions, a plane in 3 dimensions and is called a hyperplane if dimensionality exceeds 3.
The equation of a hyperplane is

where 
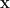


Considering the case of 2 dimensional data points, implying every data point 



The right hand side of the above equation is the equation of a line with slope ‘m’. The above formulation is to convince the reader that in 2 dimensions, a hyperplane is essentially a line.
Adding ‘b’ to both sides of the equation

Again, the RHS of the equation is the equation of a line with slope ‘m’ and intercept ‘b’. The equation of a hyperplane when written like in (1) (vectorized form) should provide you the intuition that points with more than 2 dimensions can also be easily dealt with.
The vector 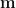
Problem Formulation
We consider a dataset containing 
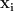




HP1 and HP2 are no ordinary hyperplanes; as per our objective of having a margin devoid of any data points lying inside it, HP1 and HP2 are selected such that for each data point
if 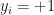
or
if 




By introducing above constraints, we have assured that the region between HP1 and HP2 will have no data points in it. These 2 constraints can be concisely written as one as follows
Having selected the above constraint obeying hyerplanes, next in line is the task of maximizing the distance 
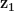

Point 

Direction of 
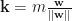
Now, 


 + b = 1")
 + b = 1")
 + b = 1")
 + b = 1")


Since 


You must realize we have landed at a very important result here. Maximizing margin
minimize
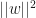
subject to 
Primal and Dual
The above formulation is known as the primal optimization problem for an SVM. What is actually solved when determining the maximum margin classifier is known as the dual of the primal problem. The dual is solved by using the Lagrange multipliers method. The motivation behind solving the dual in place of the primal is that by solving the dual, the algorithm can be easily written in terms of the dot products between the points in the input data set, a property which becomes very useful for the kernel trick (introduced later). Lets see what the dual formulation looks like.
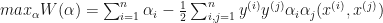
subject to
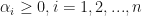
} = 0")
Seems overwhelming? Don’t bother about its complexity and just take away the crucial points explained next. Here, 

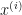




Linearly Non-Separable Data – Soft Margin & Kernels
Till now, we have very conveniently assumed our training set to be linearly separable. However, if the 2 classes are not linearly separable, or are somehow linearly separable but the resulting margin is very narrow, we have the concept of soft margin in SVMs. It often happens that by violating the constraints for a few points, we get a better margin for the separating hyperplane rather than by trying to fit a strictly separating hyperplane, as in figure shown below. If the constraints are strictly followed for all the points in this case, then we can see that the resulting separating hyperplane has a very small margin.

Thus, sometimes by allowing a few mistakes while partitioning the training data, we can get a better margin.

At the same time, the SVM applies a penalty 
)")
Looking at the equation, we can see that 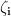
minimize

subject to 
The variable 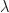
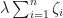
Another way of SVMs to deal with the case of non-linearly separable data points is the kernel trick. The idea stems from the fact that if the data cannot be partitioned by a linear boundary in its current dimensionality, then projecting the data into a higher dimensional space may make it linearly separable, such as in figure shown below (taken from the internet).
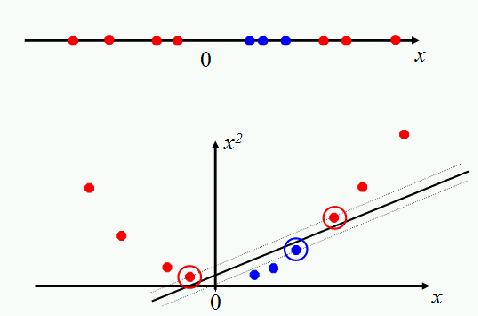
When such is the case, there will be a function 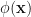
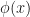
Like we mentioned before, we get the benefit of solving the optimization problem in terms of the dot products only here too, as the kernel function 

 = \phi(x).\phi(z)")
Now whats interesting to note is that often, the kernel
Conclusion
This blog was an effort to give a comprehensive idea behind the working of SVMs, right from introducing the key concepts, developing intuition about the keywords to the actual problem formulation, albeit with much of the mathematics intentionally skipped. We aimed to cover as many keywords related to SVMs as possible, nevertheless its expected that some important content was missed. Readers are encouraged to delve more into the mathematical formulation and to discuss it with us, and to also let us know about any more SVM concepts they would like to be elaborated upon in the comments. It will motivate us to cover those concepts in future posts.
Acknowledgement
- Alexandre KOWALCZYK’s blog – “SVM Tutorial”. (link)
- Non-Linear SVMs. (link)
- Lecture 2 – The SVM Classifier. (link)
- Andrew Ng, ‘Support Vector Machines’, Part V, CS229 Lecture notes. (link)
If you liked the post, follow this blog to get updates about the upcoming articles. Also, share this article so that it can reach out to the readers who can actually gain from this. All comments and suggestions from all the readers are welcome.
Happy machine learning 
Thanks for such a great article. I am new to data science, your article is very useful, finally I got some clarity about SVM.
Like
After reading your article I was amazed. I know that you explain it very well. And I hope that other readers will also experience how I feel after reading your article.
Like